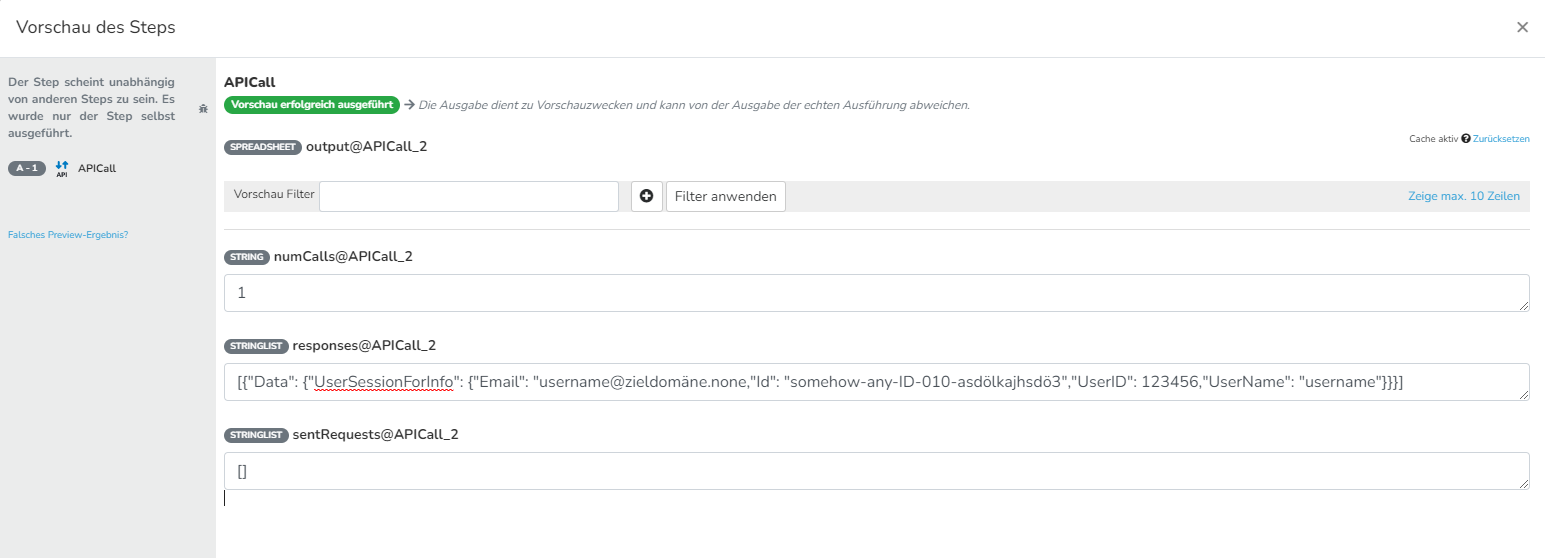
Um den Zeilenversatz zu entfernen habe ich die Zeile <#assign row = target.addRow()> aus den Sublists genommen. Jetzt passt das Ergebnis erstmal und wird in den DataStore geschrieben.
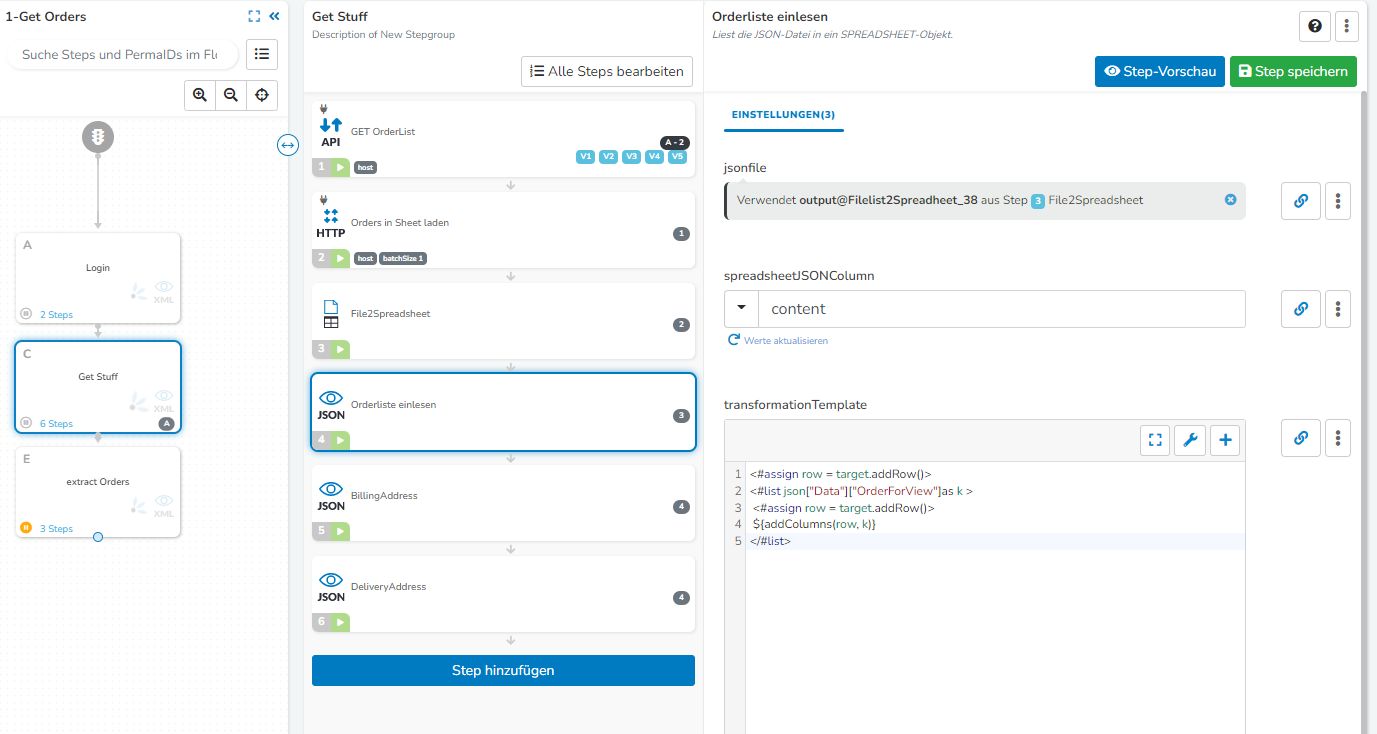
Nochmal zurück zu der Orderlist vom Anfang. Diese habe ich nun mit den Erkenntnissen aus dem Verlauf hier ebenfalls auftrennen können. Nun gibt es allerdings dort innerhalb der OrderPositionlist noch eine Itemlist. Die komplette Response war diese hier: response_1-anonymisiert.json (4,0 KB)
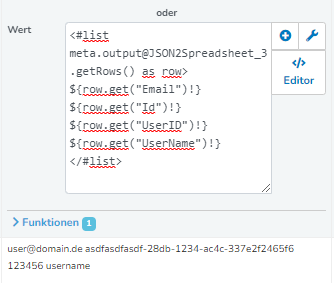
Hier mein transformationTemplate
<#assign row = target.addRow()>
<#list json["Data"]["OrderForView"] as ofv >
<#assign row = target.addRow()>
${addColumns(row, ofv, "", {'columns':['BillingAddress', 'DeliveryAddress', 'OrderPositionList'], 'mode':'exclude'})}
<#list ofv['BillingAddress'] as b>
${addColumns(row, b, "BillingAddress_")}
</#list>
<#list ofv['DeliveryAddress'] as d>
${addColumns(row, d, "DeliveryAddress_")}
</#list>
<#list ofv['OrderPositionList'] as m>
${addColumns(row, m, "OrderPositionlist_")}
</#list>
</#list>
Die OrderPositionList\Items möchte ich so auftrennen, dass pro Artikel eine Zeile entsteht.
Wichtig ist dabei nur, dass noch der Ordertoken eine Spalte hat; damit später richtig zugeordnet werden kann.
Die aktuelle Response in der Spalte „OrderPositionlist_Items“ sieht so aus
{
„DiscountAmount“: 0,
„DiscountRate“: 0,
„IndexId“: 1,
„NumberOfWithdrawals“: 2,
„OfferSourceId“: 1,
„OrderAmount“: 3,
„OrderQuantity“: 3,
„PackType“: „“,
„ParentProductEntityTypeId“: 7,
„ParentProductId“: 600574,
„ProductEntityTypeId“: 8,
„ProductId“: 872647,
„ProductName“: „Beispielprodukt1“,
„ProductSourceId“: 1,
„Remark“: „“,
„SKU“: „12345“,
„TotalAmount“: 300,
„TotalPrice“: 51.18,
„TotalValueOfGoods“: 51.18,
„UnitOfMeasure“: „ml“,
„UnitPrice“: 17.06,
„UnitPriceList“: 17.06,
„VatType“: 1,
„WithdrawalQuantity“: 50
}, {
„DiscountAmount“: 0,
„DiscountRate“: 0,
„IndexId“: 2,
„NumberOfWithdrawals“: 1,
„OfferSourceId“: 1,
„OrderAmount“: 1,
„OrderQuantity“: 1,
„PackType“: „“,
„ParentProductEntityTypeId“: 7,
„ParentProductId“: 1027349,
„ProductEntityTypeId“: 8,
„ProductId“: 1027350,
„ProductName“: „Beispielprodukt2“,
„ProductSourceId“: 1,
„Remark“: „“,
„SKU“: „23456“,
„TotalAmount“: 1,
„TotalPrice“: 164.79,
„TotalValueOfGoods“: 164.79,
„UnitOfMeasure“: „Stck.“,
„UnitPrice“: 164.79,
„UnitPriceList“: 164.79,
„VatType“: 1,
„WithdrawalQuantity“: 1
}
Hat jemand Vorschläge dazu?