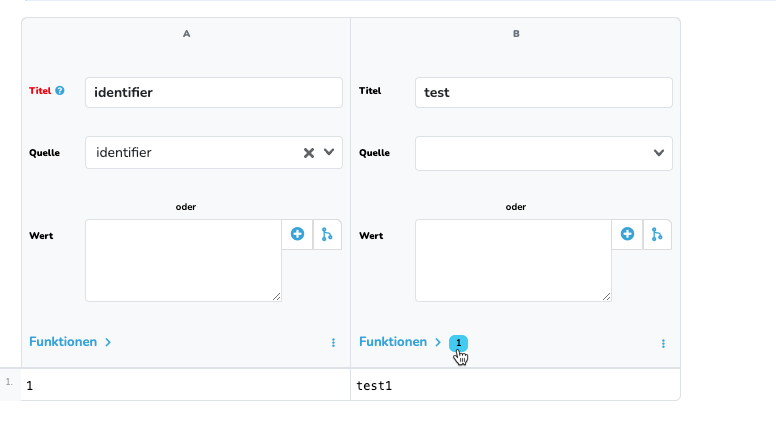
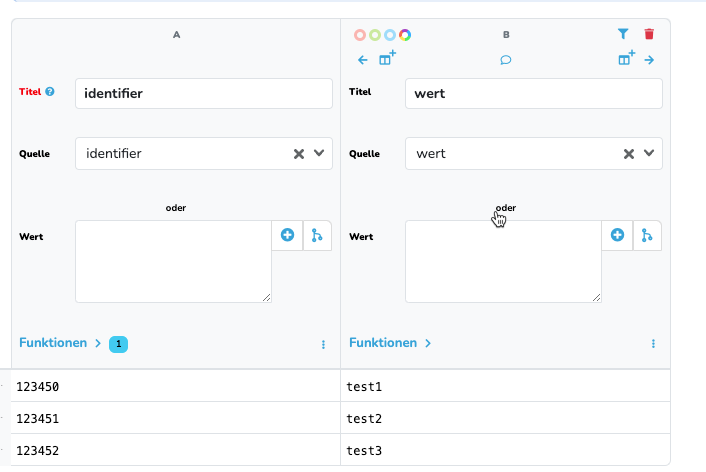
Nun habe ich im Datastore B ein weiteres Feld „test“ angelegt, wo die Wert „wert“ von Datastore A geändert werden soll.
Ich möchte nun den „identifier“ von Datastore A mit dem „key“ von Datastore B matchen und dann den jeweiligen Wert von „wert“ Datastore A in „test“ von Datastore A ändern lassen. Ich bekomme die dafür nötigen Steps nach mehreren Versuchen nicht hin.
Was habe ich probiert?
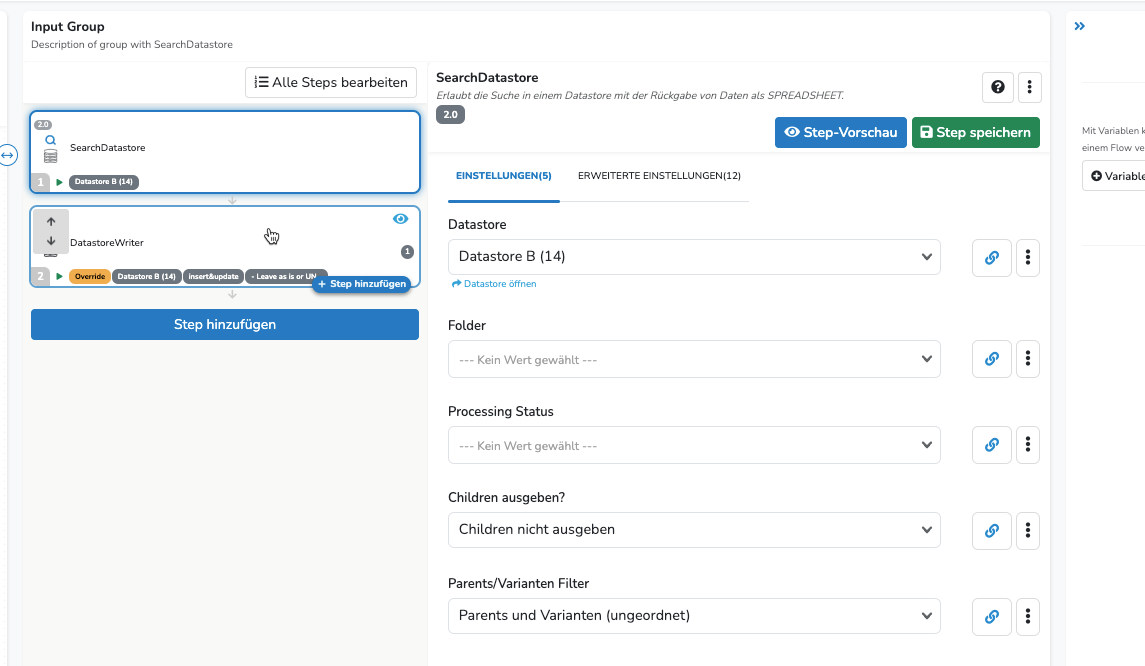
Ich habe ein SearchDatastore auf Datastore A gemacht. Um dann mit DatastoreWrite auf Datastore B die jeweiligen Werte zu aktualisieren. Hierbei bekomme ich immer die Fehlermeldung, das „identifier“ von Datastore B angegeben werden muss beim Mappen. Aber das ist die Artikelnr. 123450 usw, was mich aber in dem Fall nicht interessiert. Ich will nach „key“ mappen. So habe ich dann versucht den „identifier2“ von Datastore B mit dem Wert von „key“ zu füllen, um es damit zu mappen. Auch keine Chance. Ich habe den Step Filter und Mapper genutzt, aber auch hier sämtliche Versuche ohne Erfolg.
Das führt leider dazu, dass nun 5 Datensätze in Datastore B angelegt wurden. Ich hatte den DatastoreWriter vorher auf „nur aktualisieren“. Da passierte nichts. Daher hatte ich es testweise auf „anlegen & aktualisieren“ gestellt.
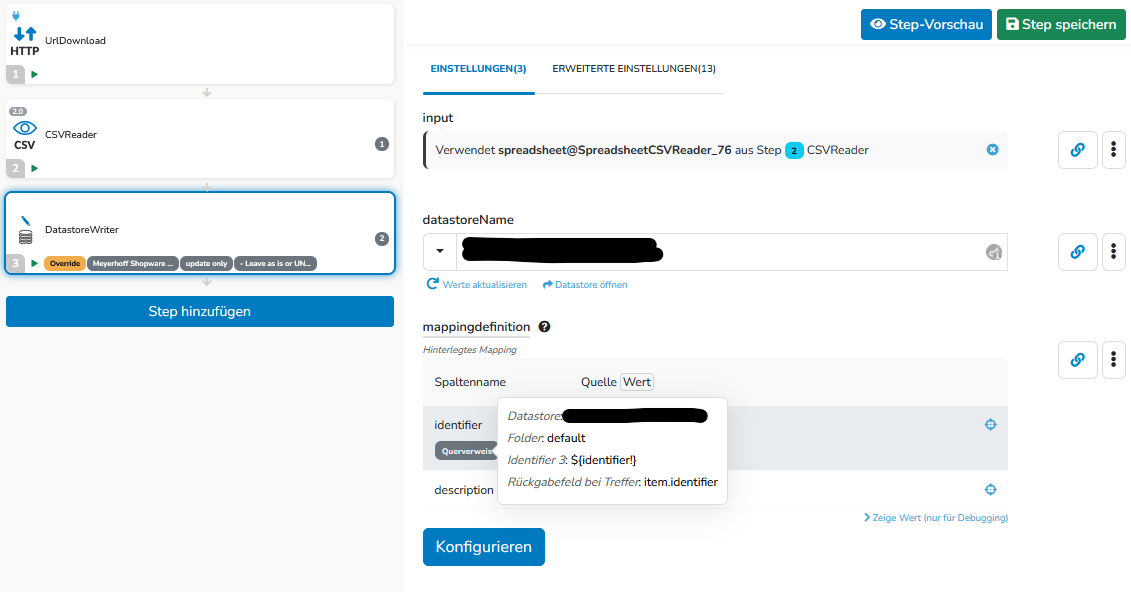
da sollten keine neuen Datensätze angelegt werden, wenn der SearchDatastore und der DatastoreWriter den gleichen Datastore verwenden. Kannst du bitte nochmal überprüfen, ob du das Mapping im DatastoreWriter wie oben im Screenshot konfiguriert hast und das identifier Feld in den erweiterten Einstellungen deines DatastoreWriters leer ist:
da sollten keine neuen Datensätze angelegt werden, wenn der SearchDatastore und der DatastoreWriter den gleichen Datastore verwenden.
Es sind nicht die gleichen Datastores.
SearchDatastore ist Datastore A und DatastoreWriter ist Datastore B, weil ich die Inhalte von A nach B aktualisieren möchte. Hier müsste „identifier“ aus Datastore A mit „key“ aus Datastore B gemappt werden. Aber hier kommt es dann zum Problem mit den identifier, wie beschrieben, was ich nicht gelöst bekomme.
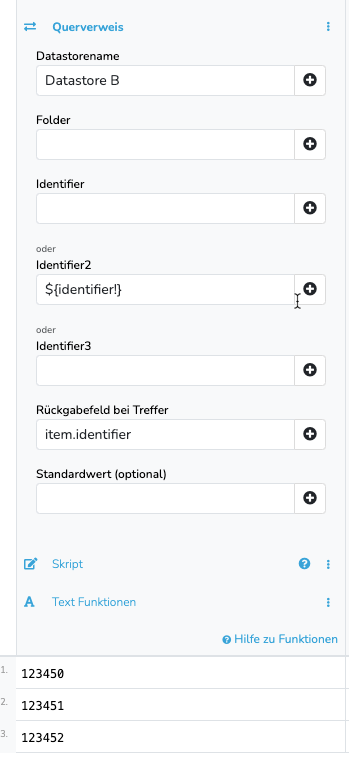
Wenn du im SearchDatastore Step auch den Datastore B verwendest und im Querverweis (siehe oben) den Wert aus Datastore A „holst“ dann sollte es funktionieren und du bekommst auch den gewünschten Wert aus Datastore A.
Der Weg den du gewählt hast (Datastore A → Datstore B) ist meiner Ansicht nach etwas umständlicher, auch wenn es auf den 1. Blick logischer erscheint. Das Problem ist, dass der „Abgleich“ ob ein Datensatz neu im Datastore ist, nur über den identifier des Datensatzes funktioniert. Diesen Wert hast du im Datastore A nicht.
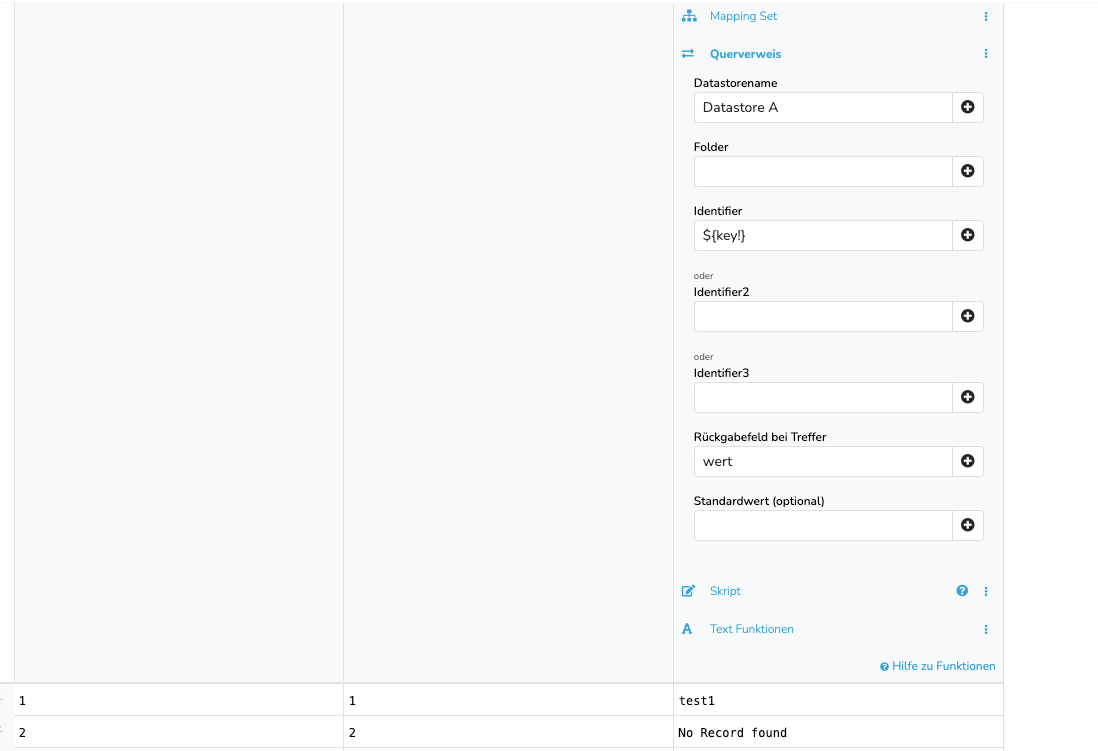
Lösen kann man das über die Querverweis Funktion. Damit du den Querverweis verwenden kannst, benötigst du aber den identifier der Datensätze aus Datastore A („key“ in Datastore B) in einem der beiden freien identifier Felder (identifier2 oder identifier3) in Datastore B.
Wenn du den Wert aus key im identifier2/3 hast kannst du folgendes machen:
SearchDatastore (Datastore A)
DatastoreWriter (Datastore B)
In der Konfiguration(Mapping) des DatastoreWriter Steps kannst du folgendes einstellen:
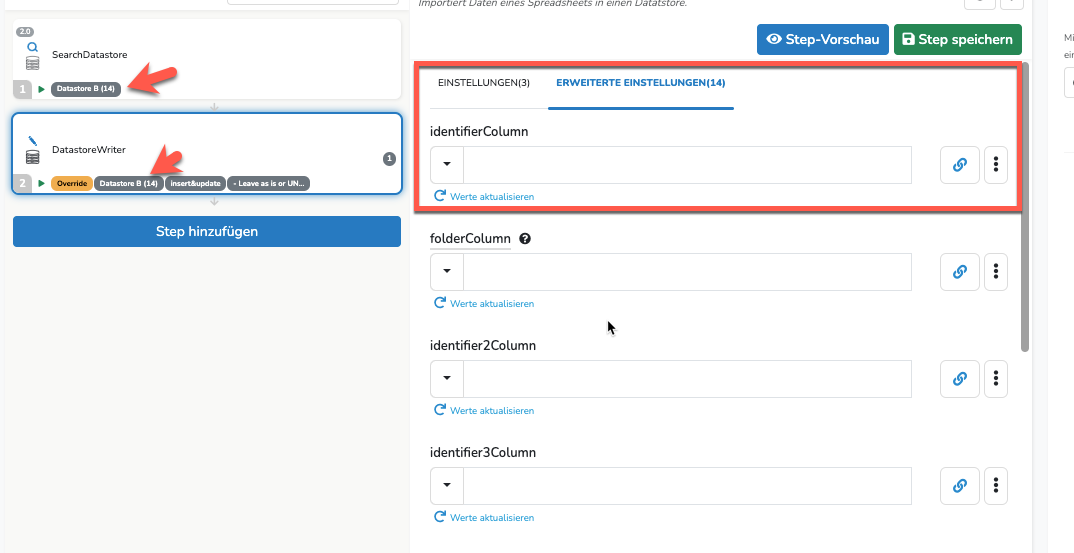
identifier Spalte im Mapping lassen und alle Spalten aus Datastore A entfernen die du nicht in Datastore B benötigst:
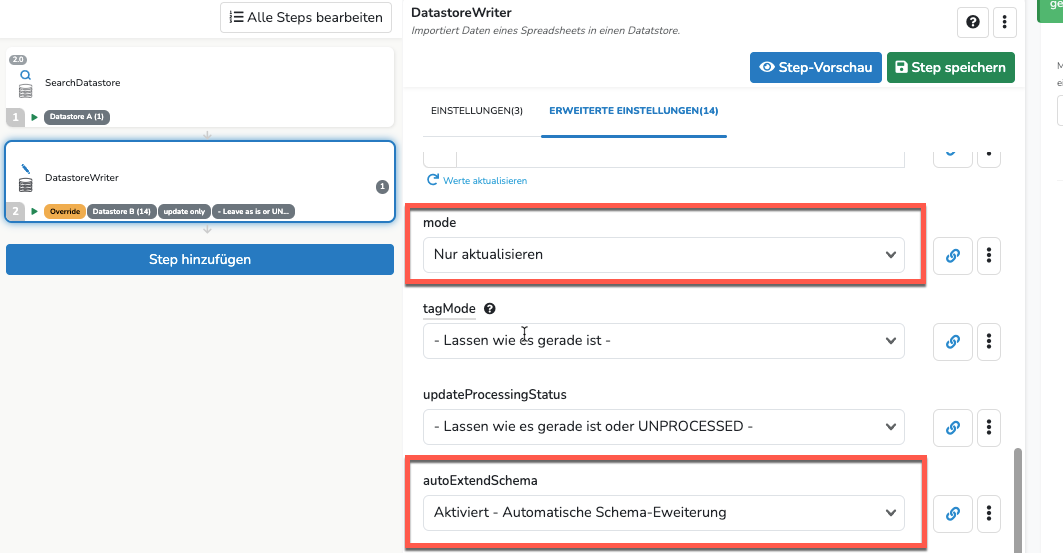
In den erweiterten Einstellungen sollte mode = „Nur aktualisieren“ ausgewählt werden, damit keine neuen Datensätze in Datastore B angelegt werden.
Eventuell ist es auch sinnvoll die Option autoExtendSchema auf „aktiviert“ zu stellen. Mit der Einstellung werden die „gemappten“ Felder aus Datastore A im Schema von Datastore B automatisch hinzugefügt. Ansonsten müssen diese manuell im Schema des Datastore B hinzugefügt werden
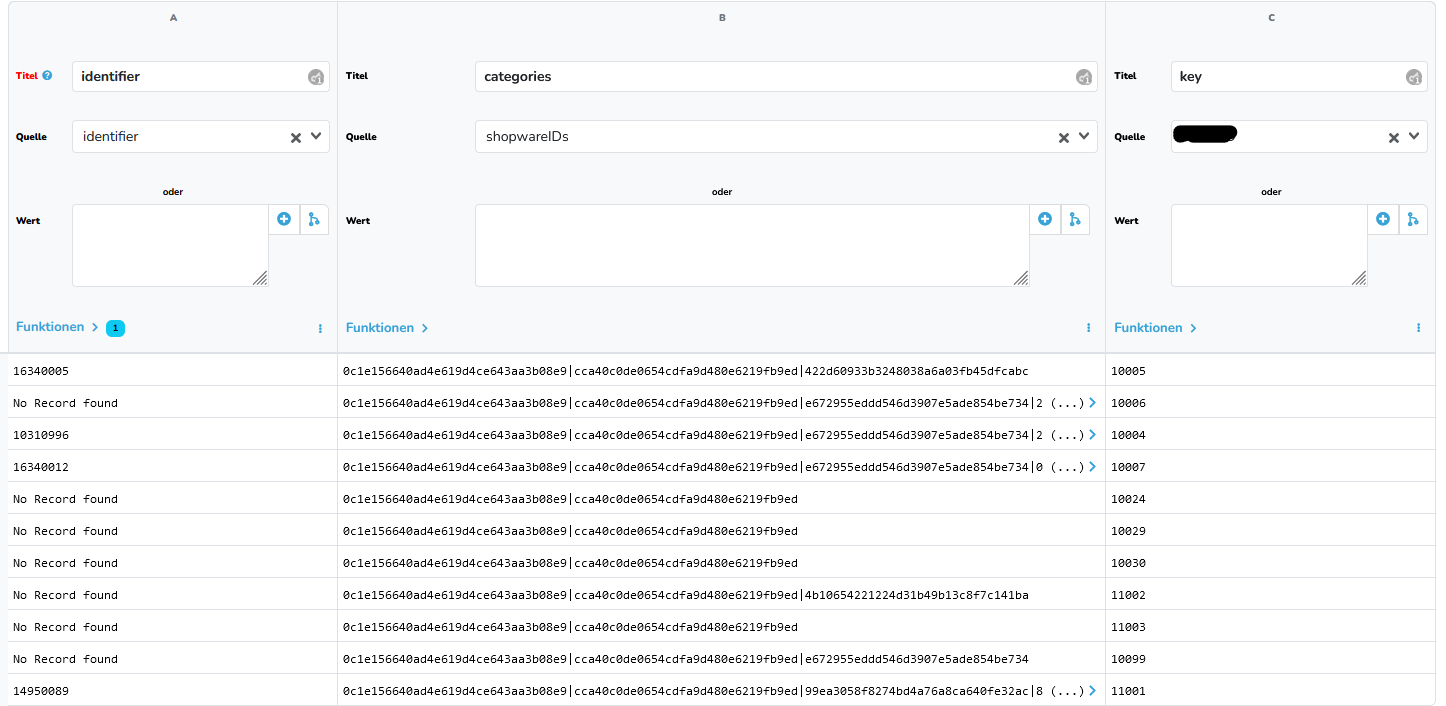
Ich erhalte oftmals „No Record found“. Das kann aber nicht sein, weil „key“ von Datastore B immer ein Wert zu „identifier“ von Datastore A hat. Ich habe sogar ein Fall, wo 1 von 8 Datensätze den Wert befüllt hat, die anderen 7 aber nicht, obwohl es den gleichen „key“ (damit auch „identifier2“ von Datastore B hat.
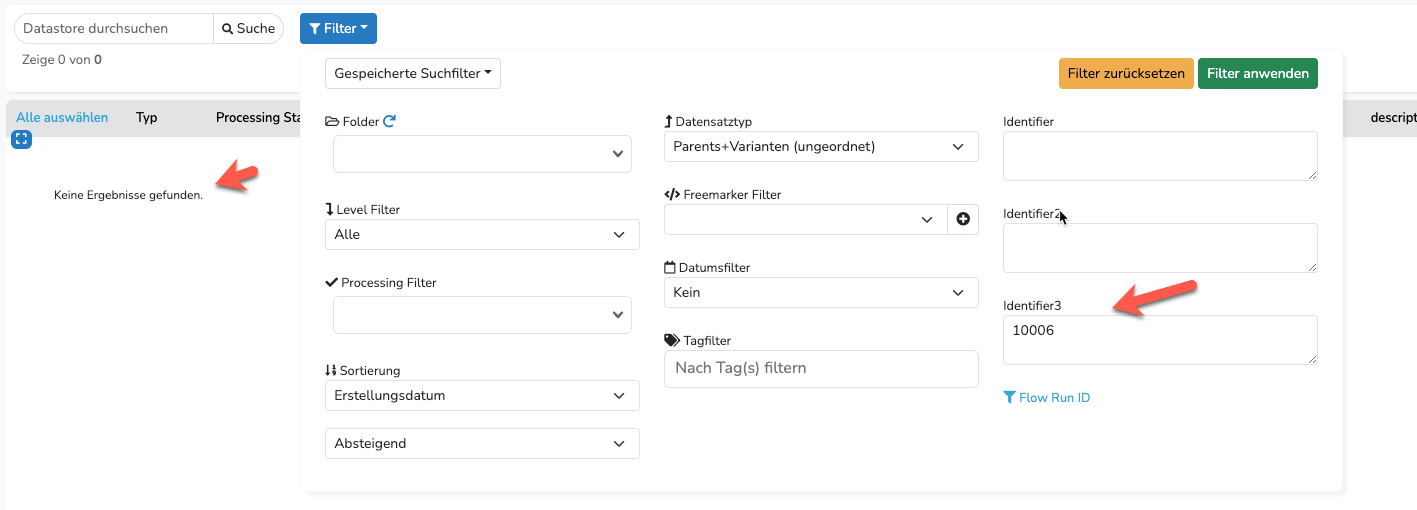
Ich habe da auch keine Leerzeichen oder sonstiges drin, was zu Fehler führen könnte. Ich habe bei dem Querverweis auch noch etwas rumgespielt. Auch bei den erweiterten Einstellungen. Nichts hilft. Es macht aber wie gesagt auch überhaupt keinen Sinn, weil die Zuweisung klar ist, wie man an der rechten Spalte im Screenshot auch sieht. Zum Beispiel die 10006 in Zeile 2 gibt es in Datastore A.
Daher meine Frage, was noch zu den „No Record found“ führen könnte?
„No Record found“ heißt, das der „key“ nicht in der im Querverweis angegeben Spalte (identifier3) des Folders („default“) des Datastores gefunden wurde. Du kannst das auch testen indem du den Datastore öffnest und über den Filter nach der Artikelnummer in identifier3 suchst:
Das liegt daran, dass der Querverweis nur einen Treffer (den 1.) liefert. Wenn du den „key“ an 8 verschiedenen Datensätzen am identifier3 des Datastores hast, wird immer nur der identifier eines Datensatzes (1. Treffer) kommen. Es wird dann entsprechen auch nur dieser eine Datensatz aktualisiert.
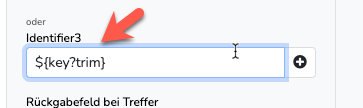
Wie du schon festgestellt hast, werden die meisten Probleme beim Querverweis durch Leerzeichen, Zeilenumbrüche oder sonstige Steuerzeichen in den Werten verursacht. Zum testen kannst du den key (z.B. 10006) auch direkt in das identifier3 Feld des Querverweises eintragen. Eventuell hilft auch die ?trim Funktion. Diese entfernt Leerzeichen und Zeilenumbrüche am Anfang und Ende.
Ein weitere, mögliche Fehlerquelle wäre die Verwendung eine Datastore Folders der nicht „default“ ist. In diesem Fall muss der Folder im Querverweis angegeben werden.
Dann ist es das Problem und das kommt bei meinen Tests auch so hin. Ich möchte aber, dass alle anderen Datensätze auch aktualisiert werden - nicht nur der Erste.
wenn der identifier2 („key“) doppelt bzw. mehrfach im Datastore B vorhanden ist, wird der Querverweis immer nur den 1. Datensatz (identifier des 1. Datensatzes) liefern. Damit du alle Datensätze aktualisieren kannst, benötigst du alle identifier (ein Zeile pro Datensatz).
Deshalb hatte ich oben geschrieben, dass es eventuell sinnvoller ist, den SearchDatastore Step mit Datastore B zu verwenden und über die Querverweis Funktion den benötigten Wert aus Datastore A zu holen und dieses Ergebnis dann wieder in Datastore B zu schreiben.
Das hat den Vorteil, dass der SearchDatastore dir ein Spreadsheet mit je einer Zeile pro Datensatz liefert.
Beispiel:
Datastore A:
identifier
wert
1
test1
2
test2
3
test3
4
test4
5
test5
Datastore B:
identifier
identifier2
key
123450
1
1
123451
2
2
123452
2
2
123453
2
2
123454
5
5
Ergebnis Spreadsheet SearchDatastore (Datastore B) + Querverweis
identifier
key
Querverweis „wert“
123450
1
test1
123451
2
test2
123452
2
test2
123453
2
test2
123454
5
test5
Das Ergebnis kannst du mit dem DatastoreWriter in Datastore B schreiben. Da du pro Datensatz aus Datastore B eine Zeile (identifier) hast, werden auch alle Datensätze in Datastore B aktualisiert.
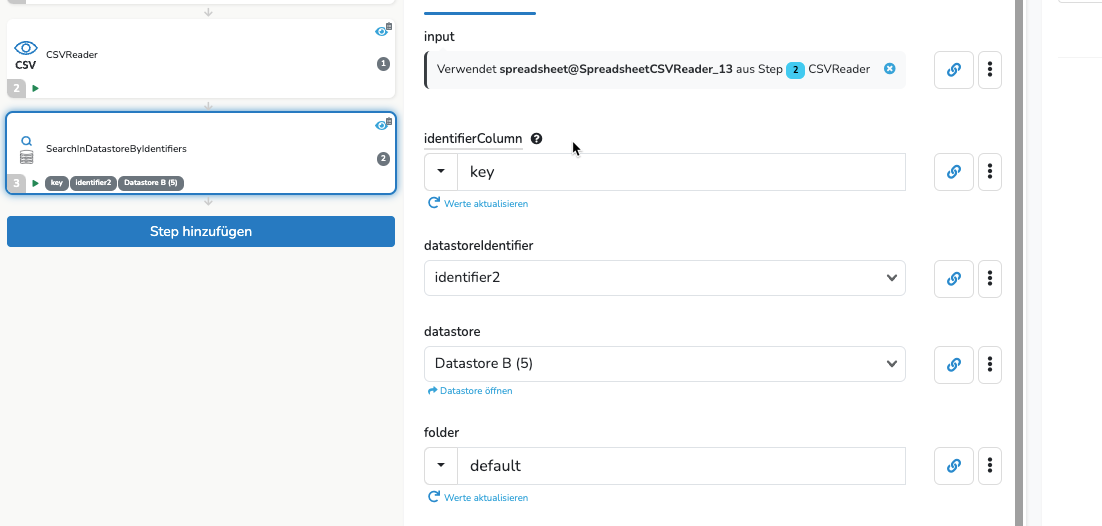
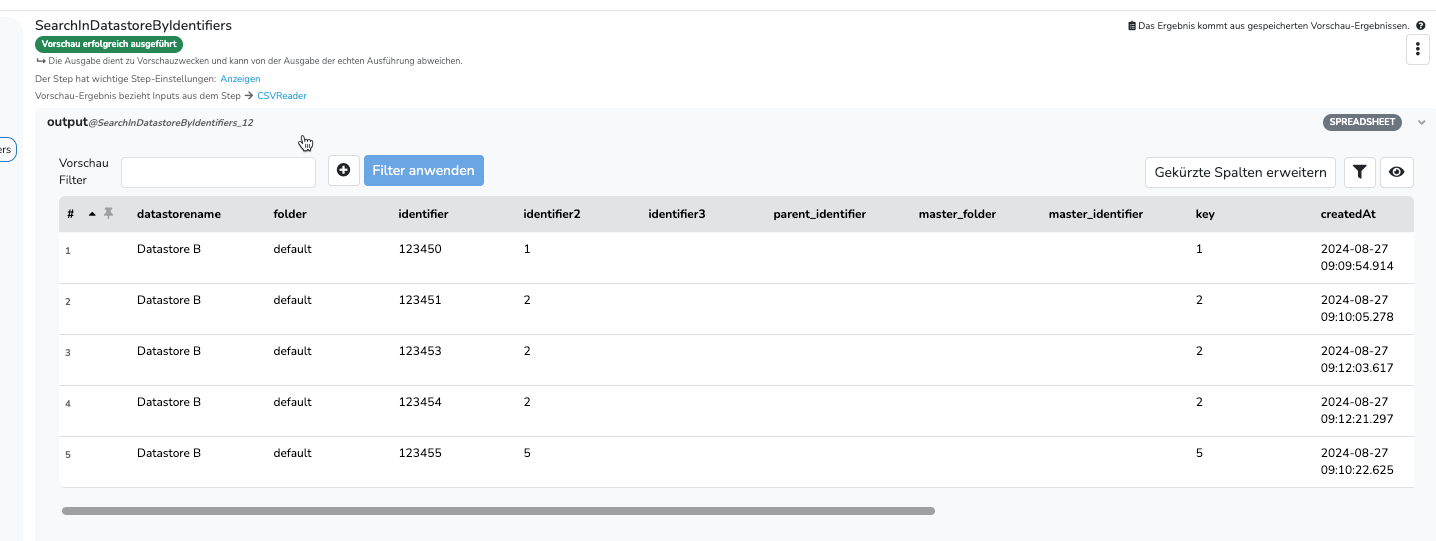
Es gibt noch einen weiteren Step, der dir eventuell hilft. Der SearchInDatastoreByIdentifiers kann alle Zeilen für einen identifier (auch doppelte) ausgeben.
Den Querverweis um an den Wert aus Datastore A zu kommen, benötigst du aber trotzdem. Der SearchInDatastoreByIdentifiers ersetzt nur den SearchDatastore Step.
wenn der identifier2 („key“) doppelt bzw. mehrfach im Datastore B vorhanden ist, wird der Querverweis immer nur den 1. Datensatz (identifier des 1. Datensatzes) liefern. Damit du alle Datensätze aktualisieren kannst, benötigst du alle identifier (ein Zeile pro Datensatz).
Deshalb hatte ich oben geschrieben, dass es eventuell sinnvoller ist, den SearchDatastore Step mit Datastore B zu verwenden und über die Querverweis Funktion den benötigten Wert aus Datastore A zu holen und dieses Ergebnis dann wieder in Datastore B zu schreiben.
Das hat den Vorteil, dass der SearchDatastore dir ein Spreadsheet mit je einer Zeile pro Datensatz liefert.