Ein Datastore-Writer auf untouchedRecords eines anderen Writers scheitert mir unregelmäßig, einige wenige Male im Monat.
Ich schreibe mir Daten mit Status SUCCESS in den Datastore, und danach die untouchedRecords als MARK_DELETE:
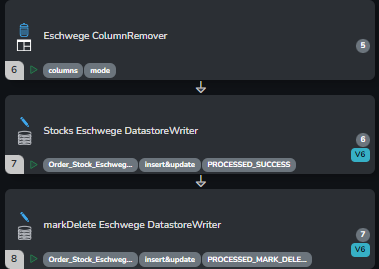
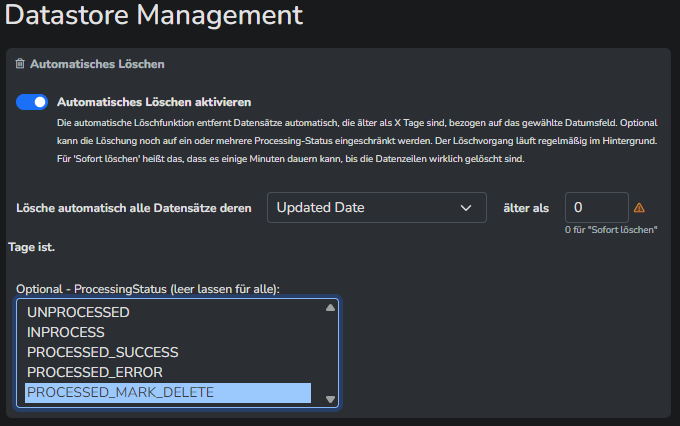
Auto-Removal im Datastore auf instant gesetzt, und auf den Status beschränkt:
Und der Fehler dann so:
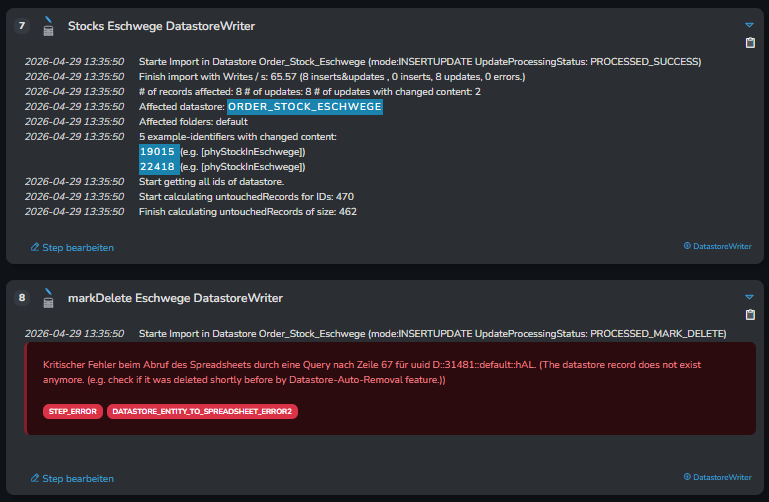
Versteh ich nicht. Im Datastore können (solange er nicht angefasst wird) keine MARK_DELETE-Einträge drin sein, weil die direkt entfernt werden.
Also muss jeder vorhandene untouchedRecords-Eintrag einen anderen Status gehabt haben in dem Moment in dem ich den DS aktualisiere.
Aber warum findet dann der zweite DatastoreWriter seinen record nicht? Bevor er nicht auf MARK_DELETE gesetzt wurde, kann er doch gar nicht verschwinden.
Denk ich falsch?
Danke im Voraus, Daniel