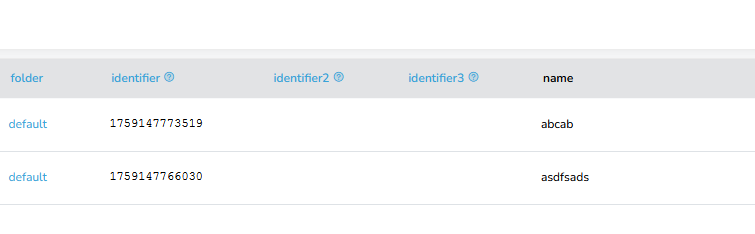
mir ist aufgefallen, dass der Datastore Writer die Werte in einer Spalte nicht überschreibt werden, wenn der neue Wert leer ist. Beispiel: Spalte „Autor“ in der CSV Datei gestern hatte den Wert „Tim“. Der Export heute ist in der Spalte „Autor“ = „“. Wenn ich den Flow dann nochmal laufen lasse, steht immer noch „Tim“ im Datastore.
Ich glaube, das hat in der Vergangenheit auch immer funktioniert. Könnt ihr mir da bitte einmal Rückmeldung zu geben?
von wo kommt die CSV? Wird die vorher von einem anderen Step heruntergeladen oder lädst du die normal als Datei/Variable hoch in dem CSVWriter und hast du sie eventuell ausgetauscht?
ich setze mir die Datei, die letzten Endes im Datastore landet, aus 3 verschiedenen CSVs zusammen, die ich via FTP Download → CSV Reader → Mapper → SpreadsheetAppend → Mapper (Gruppierung auf SKU) zusammenfüge.
um einfach mal erst mal ein paar Fehler auszuschließen. Bei dem Append und anschließender Gruppierung kannst du auch sicher gehen, dass nicht eine weitere Zeile etwas in Autor steht, die durch die Agggregatfunktion „überschrieben“ wird?
Vielleicht kannst vor dem Datastorewriter einen CSVwriter setzen und anschließend dir die CSV in einem StoreDebugFile speichern. Einfach um zu schauen, ob bei der Ausführung Autor auch wirklich leer ist.
Also Grundsätzlich um auf deine Frage zurückzukommen, sollte ein leeres Feld, wenn die Quellspalte gesetzt ist, auch im Datastoer als leer geschrieben werden.
Wichtig ist aber, dass das Feld auch wirklich leer ist und nicht null, also gar nicht erst vorhanden.
danke für deine Rückmeldung! Ja ich hatte mir den Input vom Datastore Write als CSV ausgeben lassen und auch dort ist das Feld „Autor“ leer. Also der Input sieht für mich vollkommen korrekt aus.
ich stolpere grade auch über das Thema, du bist nicht allein ;). @synesty-Lukas Bitte prüfen! Man kann Werte in Datastores einfach nicht mehr mit leeren Werten überschreiben.
an der Logik hat sich nichts geändert. Was sein kann ist, dass dein Value @EG-Interfaces null anstatt leer ist. Das sieht imm Mapper gleich aus, hat aber den Effekt, dass im Datastore der „leere“ Wert nicht geschrieben wird.
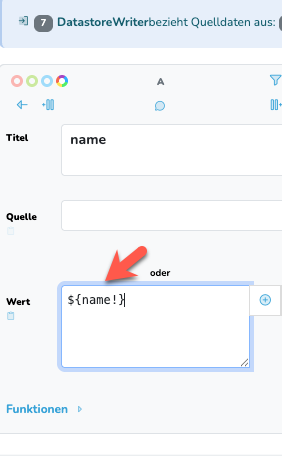
Um sicher zu gehen, dass dieser leer überschrieben wird, kannst du im Skript-Feld ${_currentValue!} setzen. Dann wird null auch als leer gewertet und im Datastore entsprechend gesetzt.
ich hänge mich mal mit rein. Der DS Writer Step überschreibt Werte im Datastore nur, wenn diese im input-Spreadsheet „gesetzt“ sind. Das ist nicht immer der Fall, auch wenn es z.B. in der Vorschau des input - Spreadsheets so aussieht.
Die Werte werden beim Import pro Zeile (pro „identifier“) betrachtet und es gibt einen Unterschied zwischen nicht gesetzten (null) und leeren ("") Werten. Wenn ein Wert in einer Zeile/Spalte nicht gesetzt (null) ist, dann wird der vorhandene Wert im Datastore nicht überschrieben.
Nicht gesetzte Werte können auf verschiede Arten zustande kommen, z.B.
wenn im Mapping weder eine Quelle, noch ein Wert (inkl. Funktionen) gesetzt ist
Es beim gruppieren kein Ergebnis gibt (z.B. „erster nicht-leerer Wert“ ausgewählt, aber nur leere/nicht gesetzte Werte vorhanden)
beim JSONReader / XMLReader, z.B. bei einer Zeile ein Spalte nie hinzugefügt wird (mit ${row.addCol("name", "..." )})
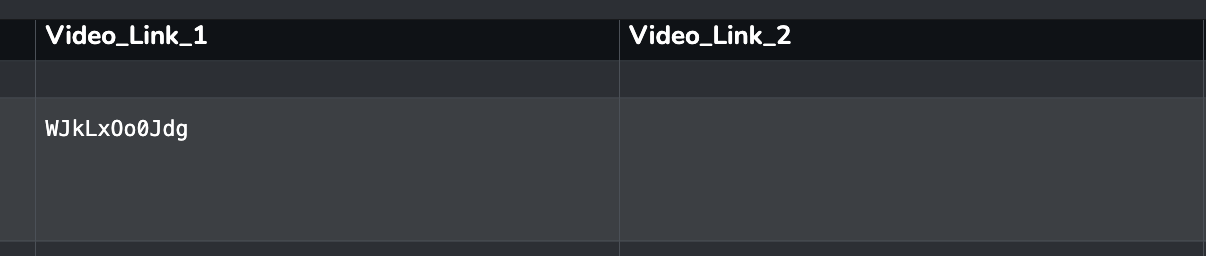
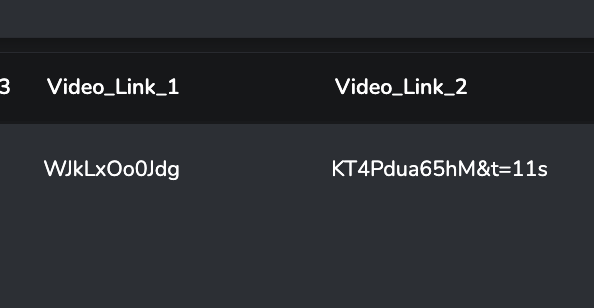
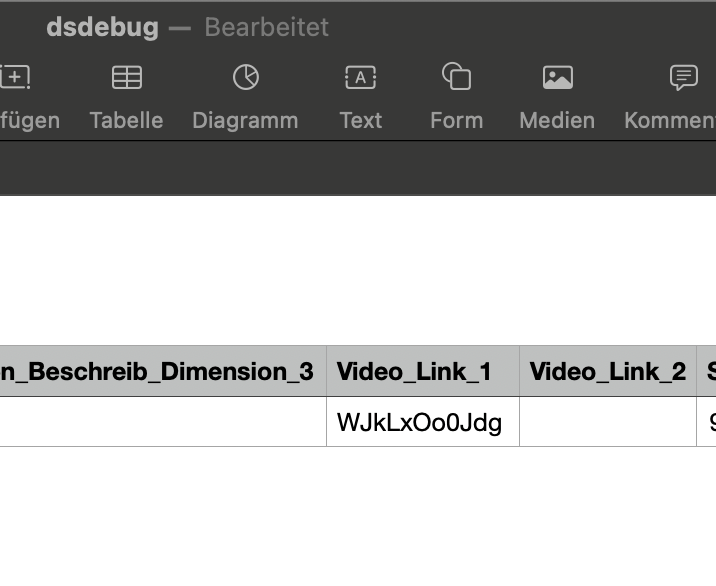
In diesem Fall wird bei id = 2 kein Wert in der Spalte „video_link_2“ gesetzt. D.h. beim Import in den Datastore wird der vorhandene Wert nicht überschrieben
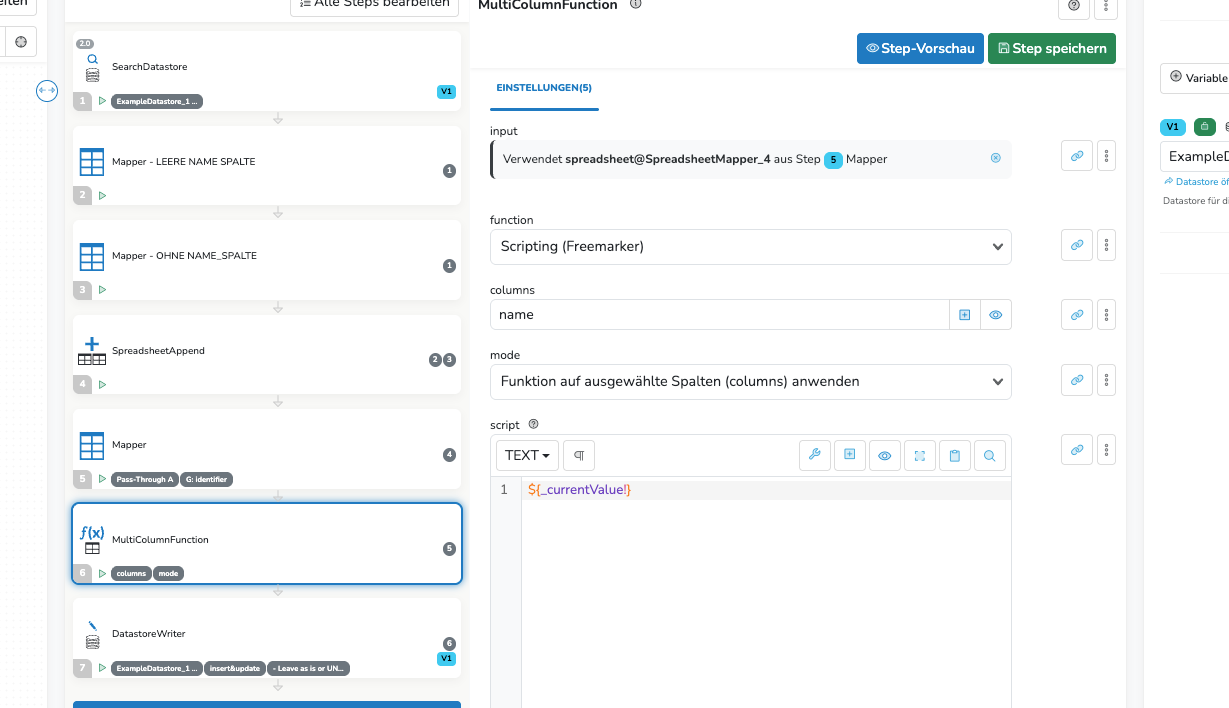
In deinem Beispiel - Flow gibt es zwei Probleme:
Problem: Es wird nie ein Wert in der Spalte „name“ gesetzt. Im ersten Mapper ist keine Quelle ausgewählt, im zweiten Mapper ist die Spalte gar nicht vorhanden.
Problem: Bei der Gruppierung im Mapper (Step 5) wird als Standard Aggregatfunktion (in der Spalte „name“) „erster nicht-leerer Wert“ verwendet. Es gibt aber keinen „nicht leeren“ Wert. Das Ergebnis der Gruppierung ist dann auch null
Wenn der Wert im Datastore immer überschrieben werden soll, wenn dieser nicht gesetzt ist, gibt es verschiedene Möglichkeiten. Im einfachsten Fall kann man den Spaltenname + Default value operator im Wert-Feld des DS Writer Mapping angeben oder wie Lukas geschrieben hat ${_currentValue!} in die Skript Funktion.
Man kann auch den MultiColumnFunction Step dafür verwenden. Wenn die Spaltennamen nicht bekannt sind, dann kann man im „columns“ input auch mit wildcard (*) arbeiten.
danke für die detaillierte Erklärung - dann gibts nochmal eine MultiColumnFunction vorm DS Writer, das passt für mich - muss man nur erst einmal verstehen, wie genau das alles “unter der Haube” abläuft