Hallo Team,
folgendes Problem: Ausgangs-Spreadsheet hat aggregierte Spalteninhalte, z.B. mehrere EANs (1=…,8=… usw) und mehrere Preise. Da sich diese Inhalte ändern können, kann ich die Spalten nicht direkt parsen - sobald ein Barcode-Typ im Backend des Klienten hinzugefügt werden würde, würde ich diesen beim Einlesen aufgrund der starren Step-Konfiguration ja nicht mehr erwischen, analog bei den Preisen. Also habe ich beide Spalten so aufbereitet, daß sie von anschließenden JSONReader-Steps geparst werden - diese Outputs würden aufgrund der list-Anweisung dann ja alles beinhalten, was ggf. in Zukunft da noch dazukommt. Jetzt kommt mein Problem: Wenn ich diese Outputs dann wieder zusammenfügen will, muß ich das ja wieder in einem Mapper machen und dann über eine gemeinsame Spalte gruppieren, die Spalten aggregieren usw. Das bedeutet aber, daß ich nichts gewonnen habe - die Mapper-Konfiguration ist ja dann wieder starr. Lasse ich den Flow morgen laufen, und es gibt einen neuen Preis, taucht er in diesem Mapper nicht auf. Gibt es irgendeine Möglichkeit, die Gruppiererei irgendwie hinzubekommen, indem ich zwar die gemeinsame Spalte zum Gruppieren nenne, die anderen Spalten aber nicht explizit angegeben werden, sondern stattdessen die Outputs der JSONReader-Steps herangezogen werden? Oder irgendeinen anderen Weg, ggf. neu hinzukommende Spalten zu erfassen, i.S.v. dynamischer Erweiterung des Mappers?
danke für deine Beschreibung. Kannst du das bitte noch als Beispiel in tabellarischer Form zeigen, denn in Textform ist es nur schwer nachvollzuziehen.
Als Beispiel wie man Tabellen erstellen kann:
Hi Lukas,
das läßt sich eigentlich überhaupt nicht vernünftig in Tabellenform pressen…Aber ich meine, daß man das doch gut verstehen kann: Ausgangsspreadsheet beinhaltet sowas:
Preise
1=12.34;2=45.67;5=31.23
Wenn ich das direkt im Mapper parse, erhalte ich meinetwegen die Spalten Preis_1, Preis_2, Preis_3
Ich weiß aber nicht, ob mein Klient sich einfallen läßt, einen Preis5 anzulegen - wenn ja, muß auch dieser erfaßt werden. Geht aber nicht, weil im Mapper ja (nach diesem direkten Parsen) explizit nur Preis_1, ~2, ~3 spaltenmäßig drinstehen. Ich brauche also eine Möglichkeit, ALLE Preise zu ermitteln. Das ginge, wenn man dem Mapper „sagen“ könnte, daß er sich automatisch erweitern soll, wenn ein Preis hinzu kommt. Alternativ kann ich das aggregierte Preisfeld durch einen JSONReader jagen und erhalte aufgrund der dortigen list-Anweisung alle Preise im Output. Die könnte ich nun in eine Excel kippen, und das wär’s - aber ich muß sie noch mit den Restdaten aus dem Ausgangs-Spreadsheet zusammenbringen. Und dann habe ich wieder dasselbe Problem, weil ich dazu einerseits das Ausgangs-Spreadsheet und andererseits den JSON-Output über eine gemeinsame Spalte gruppieren und das ganze dann aggregieren muß - und das geht eben nur im Mapper, sprich: Wieder mit festgelegten Spalten.
Ich hoffe, es ist jetzt angekommen, wo das Problem liegt?
ich glaube, wir hatte mal dasselbe Problem. Du möchtest im Endeffekt einen Aggregations-Modus für Spalten vorgeben, ohne jede Spalte im Voraus zu kennen, korrekt? Also eine Kombination aus der Gruppierung und dem Pass-through-Mappingmodus, z.B. wende auf alle nicht genannten Spalten die Aggregation Eindeutige Werte auflisten an.
Soweit ich mich richtig erinnere, wird bei der Kombination aus Pass-through und Gruppierung für alle nicht-genannten Spalten die Standard- Aggregatfunktion ( Wert der ersten Zeile ) angewandt. In unserem Fall war das glücklicherweise die richtige Funktion. Mir war aber auch aufgefallen, dass es keine Möglichkeit gibt, eine andere Aggregatfunktion zu benutzen, ohne die einzelnen Spalten explizit zu konfigurieren.
Wenn du eine andere Funktion benutzen muss, fällt mir auf die schnell nur eine Möglichkeit ein. Man kann einem Mapper auch die Mappingdefinition aus einem vorherigen Schritt vorgeben. Du könntest also in einem HTMLWriter dynamisch die Mapping-Definition als JSON für deine Gruppierung schreiben und dort eben auch die korrekte Aggregatfunktion auswählen. Hier kannst du dann alle Spalten berücksichtigen, welche in deinen Eingangsdaten vorkommen.
Hallo Gustav,
Du hast genau erfaßt, was mein Problem ist. Vielen Dank für Deine Ideen - tatsächlich brauche ich „erster nicht-leerer Wert“ für alles, was rechts neben der Gruppierungsspalte steht. Aber sehr interessant, was Du über die Möglichkeit schreibst, die Mapping-Definition selbst zu schreiben - darauf bin ich noch gar nicht gekommen. Ich werde da mal ein bißchen herumexperimentieren.
Da fällt uns in der Tat nichts ein, wie man das aktuell machen könnte.
Einzig eine anderer pragmatischer Ansatz wäre:
Angenommen du weisst, dass es sich um z.B. max 25 Preise handeln wird, dann könntest du ja schon 25 Preisspalten anlegen, auch wenn du aktuell nur 5 brauchst. Die Frage ist, ob die Anzahl Preise wirklich unendlich hoch werden kann, oder ob es sich eher im zweistelligen Bereich bewegt.
Ja das ginge rein technisch. Aber von uns wird dazu keine Empfehlung kommen, da die MappingDefinition Interna ist, die sich auch ändern kann. Wir werden keine Garantie abgeben, dass solche „Experimente“ bis in alle Ewigkeit funktionieren.
Wir nehmen das Thema mal mit und schauen, ob uns dazu etwas einfällt.
Ja, das ist vermutlich die einfachste Lösung.
Ich überlege grade, ob es noch andere Situationen gibt, wo das nicht reicht. Mir fallen so auf Anhieb keine ein.
Aus meiner Sicht müßte es aber so konfigurierbar sein, daß man etwa angeben könnte: "Alles was links von der Gruppierungsspalte („GS“) steht: Erste Aggregatfunktion, alles rechts davon: Zweite Aggregatfunktion. Das ist bei mir eigentlich immer so. In dem Zusammenhang vielleicht noch ein Verbesserungsvorschlag: Ich habe Mapper A mit zehn Spalten, die letzte Spalte ist die GS. Dann habe ich Mapper B mit vierzig Spalten, erste davon ist die GS. Ich gruppiere beide und aggregiere danach - ab der elften Spalte soll nun alles auf „Wert der letzten Zeile“ gesetzt werden. Es wäre super, wenn ich das nun nicht für jede Spalte einzeln angeben müßte. Es gibt zwar die Funktion
aber die kann ich eigentlich nie nutzen. Wenn es da eine zusätzliche Option gäbe „für alle folgenden Spalten übernehmen“, würde mir das jede Menge Klickarbeit abnehmen. Dann würde ich einfach die erste Spalte aus dem zweiten Mapper einstellen, auf den Button klicken, fertig. So muß ich mir immer so behelfen, daß ich die Regel, die für die meisten Spalten zutrifft, auf alle anwende und dann die anderen manuell einstelle. Ist aber sehr ineffizient (und ggf. auch fehleranfällig).
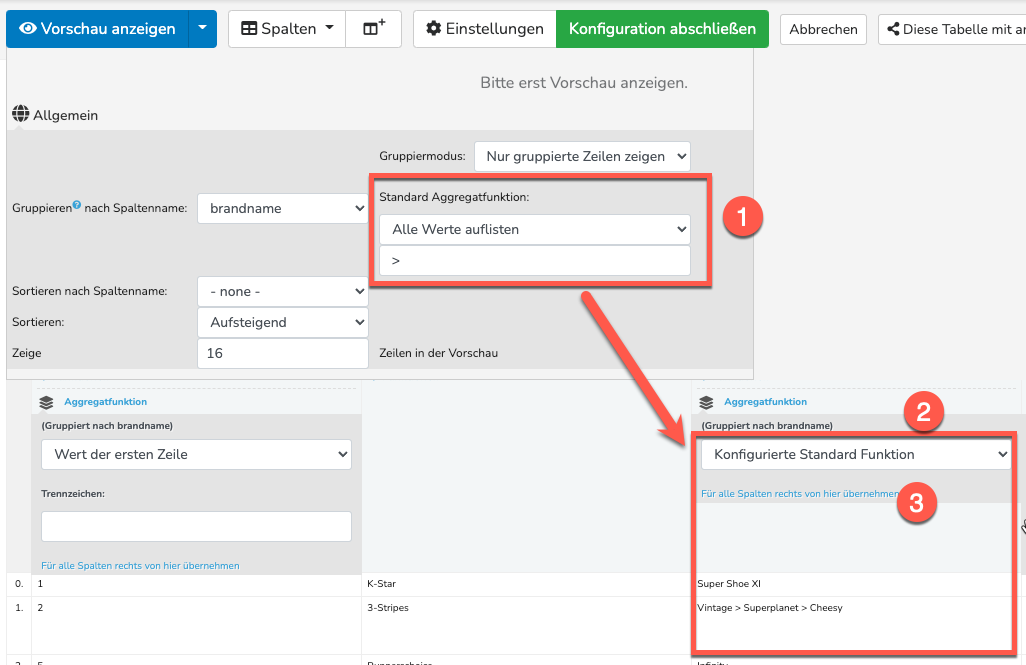
Im Mapper kann man ab Release zusätzlich eine Standard-Aggregat Funktion definieren (1).
diese wird mit dem bisherigen Default „Wert der ersten Zeile“ vorbelegt sein
in den Spalten wird der neue voreingestellt Wert sein „Konfigurierte Standard Funktion“ (2). D.h. wenn oben „Wert der ersten Zeile“ ausgewählt ist, dann greift das. Stellt man in der Spalte direkt etwas anderes ein (so wie bisher) dann greift entsprecht die Konfiguriation der Spalte. (Spalte hat Vorrang vor Standard-Funktion)
die Standard-Aggregat Funktion greift auch für alle „unbekannten Spalten“, die durch passThroughMode durchgeschliffen werden (sprich, die erst zur Ausführung bekannt werden). Das sollte diesen Fall lösen der hier diskutiert wurde.
der Link (3) um die gewählt Funktion auf weitere Zeilen anzuwenden wurde geändert und heißt jetzt „Für alle Spalten rechts von hier übernehmen“. Wer wie bisher die Funktion für „alle“ Spalten haben möchte, der fängt einfach in der ersten Spalte an.
Wir hoffen, dass wir mit dieser Erweiterung die meisten Fälle abdecken.
Feedback ist willkommen.