Ich kam jetzt heute zu (fast) nichts bzgl Prüfung, aber kann noch ein paar Details nachreichen. Es war schon sehr spät gestern:
Hab ich gemacht, es kommt nur genau ein Artikel überhaupt an: die Variante ID 1001.
Das ist der erste Artikel, der aus der API purzelt (die 1000 ist inaktiv). Alles danach wird verworfen 
Ich kann das Verschwinden auch schon per Vorschau eingrenzen:
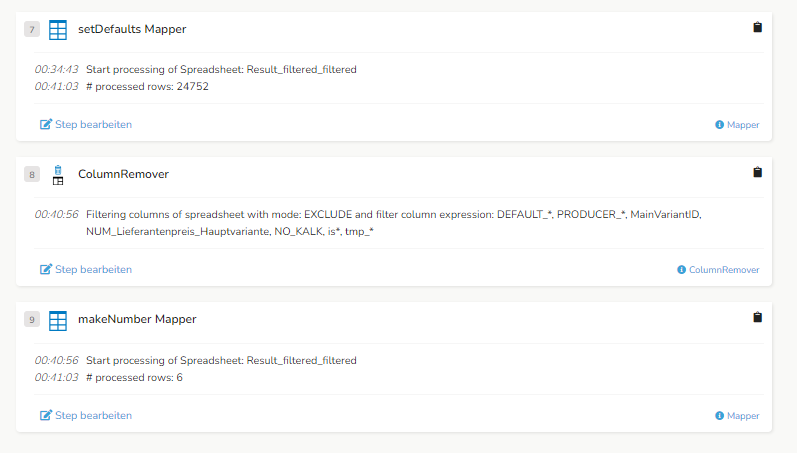
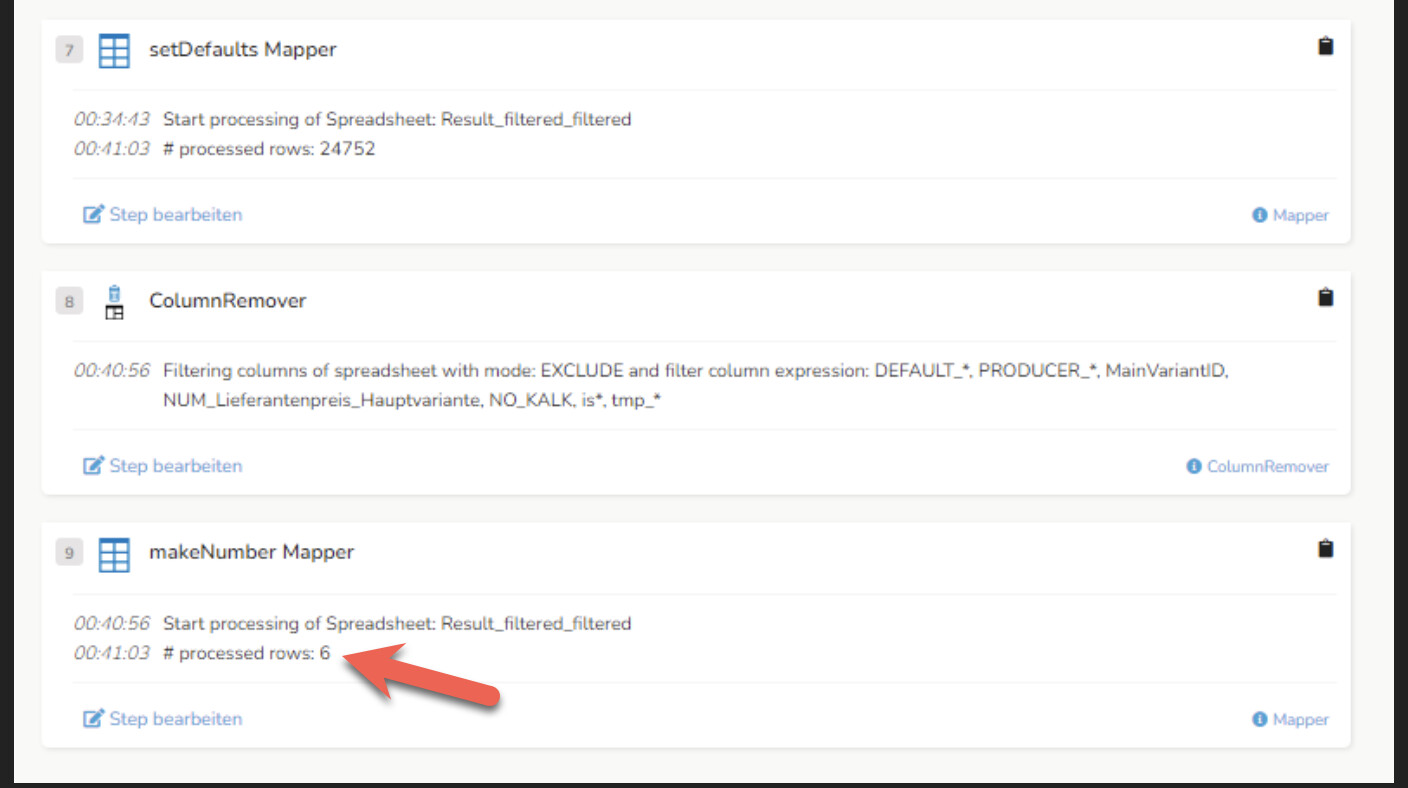
- der „Pflanzen gemischt Mapper“ gibt mir noch fünf Ergebnisse (vermute der Rest wurde vorab weggefiltert)
- der darauf folgende „setDefaults Mapper“ hat dann plötzlich nur noch eine Zeile
Der setDefaults ist auch einer der Steps, die ich kürzlich überarbeitet habe. Spalten umbenannt, zugefügt, bisschen Freemarker-Skripting direkt im Wertfeld. Aber wie führt das dazu dass Zeilen verschwinden?
Hauptsächlich passiert darin sowas
<#assign default = "DEFAULT_" + _sourceTitle!>
<#assign old = "OLD_" + _sourceTitle!>
<#if (row[old]! == "" || row[old]! == "NOT_FOUND")>
${row[default]}<#else>${row[old]}
</#if>
Also ich habe drei Spalten
Und befülle Foo mit dem Wert von OLD wenn vorhanden, und ansonsten mit dem DEFAULT.
Gleich zwei, jeweils in ner eigenen Gruppe:
- ein Segment das prüft ob
Foo (und ne handvoll andere) sich geändert hat im Vergleich zu OLD_Foo, und wenn ja geht das in einen PlentySetVariationProperties sowie PlentyUpdateVariations. Ende.
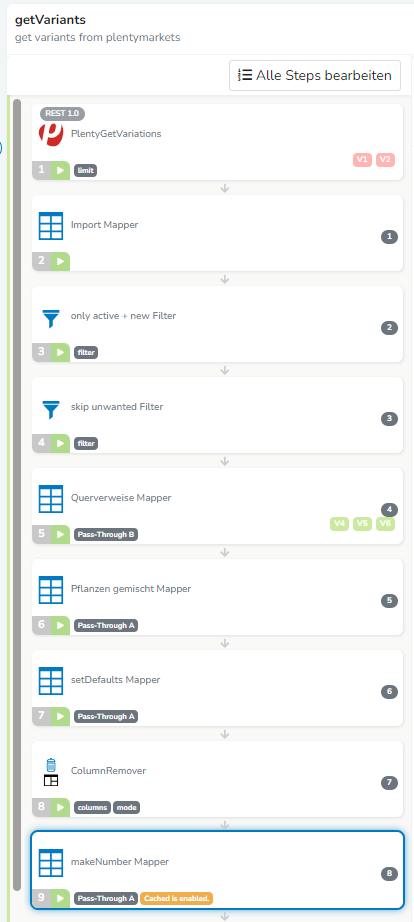
- danach gehts mit der eigentlichen Verarbeitung weiter, ein paar Filter, viele Mapper. Danach weitere Gruppen. Aber hier ist ja schon leer.
Erster Step ist bei der ersten Gruppe ein Mapper, und bei der zweiten ein Filter, der auf leeren UVP prüft. Der sollt von ausreichend Varianten erfüllt werden.
Sehr komplexes Ding, ich versuchs mal:
Vor dieser Gruppe kommen nur „geschlossene“ Gruppen, die am Anfang was abrufen, und es am Ende in einen Datastore schreiben.
Du siehst: ich hab jetzt den makeNumber-Step auf Cache gesetzt, es ist definitv der der mehrfach konsumiert wird.

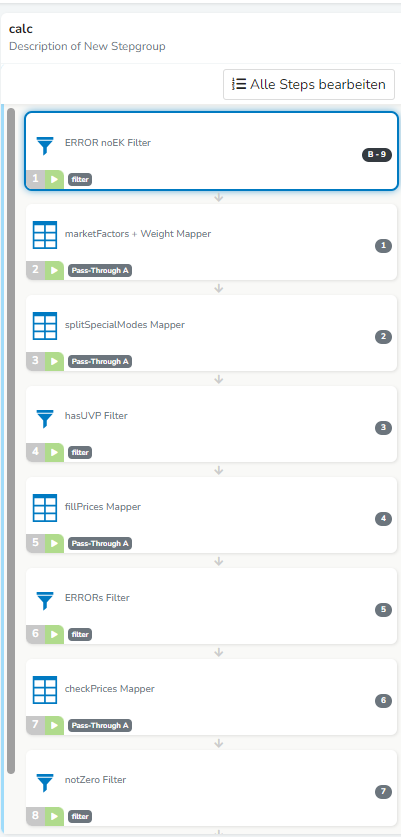
Das ist der erste Konsument, abgeschlossene Gruppe
Hier geht dann der eigentliche Ablauf weiter.
Danach kommt eine Debug-Gruppe (schreibt CSV von was ich grade brauche), und zwei Gruppen die Eigenschaften bzw Preise setzen, jeweils noch mal mit nem Filter.
Ich hab jetzt auf jeden Fall mal:
- eine CSV vom setDefaults geschrieben
- den Cache im makeNumbers aktiviert.
Ich stoß das jetzt mal an, das dauert sicher einige Stunden, bis dahin bin ich afk, ich meld mich dann später/morgen/Montag wieder mit was ich raus gefunden habe.
Bis denn, Grüße & schönes WE
Daniel