Ein klassisches Problem bei der Integration von Lieferanten für Bestandsupdates ist, dass Datensätze nicht mehr in der Lieferantendatei enthalten sind, die am Vortag bzw. beim letzten Abruf noch enthalten waren. Meist betrifft das ausgelaufene Artikel, die aus dem Sortiment des Lieferanten genommen wurden. Anstatt also den Datensatz mitzuschicken und als „ausgelaufen“ zu markieren, kommt dieser Datensatz gar nicht mehr in der Datei mit.
Die Anforderung ist dann, genau diese Artikel zu identifizieren und im eigenen Sortiment ebenfalls zu entfernen oder auf Bestand=0 zu setzen.

Bezogen auf die Grafik bedeutet das, dass man die Artikel auf der rechten Seite herausfinden will. (Delta)
Lösung:
Lösen lässt sich das Problem nur, wenn man sich immer alle Lieferantenartikel in einem Datastore speichert, damit man den Vergleich machen kann, welche Artikel am Vortag noch vorhanden waren und heute aber nicht mehr.
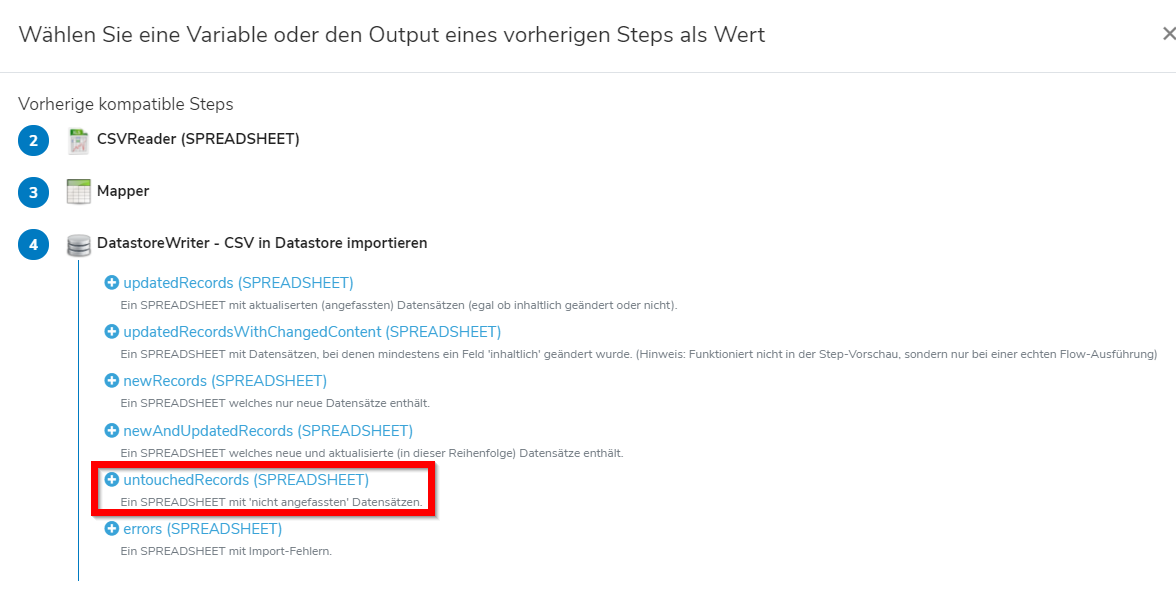
Ein möglicher Flow sieht dann aus wie im Screenshot 1 dargestellt:
- Zunächst wird die Lieferanten Datei abgerufen, gemappt und in einen Datastore importiert (Step 1 - 4).
- Der SpreadsheetDatastoreWriter (Step 4) stellt als Resultat ein Spreadsheet mit den nicht aktualisierten Datensätzen (untouchedRecords) zur Verfügung (nach aktivieren des untouchedRecordsMode in den erweiterten Einstellungen)
- Diese „nicht angefassten“ Datensätze können mit einem Mapper bearbeitet (z.B. Stock=0) und wieder in den Datastore importiert werden (Step 5 - 6)
Screenshot 1:

Screenshot 2:
Wie kann man dieses Vorgehen testen?
Dazu erstellt man sich 2 Test-CSV Dateien und importiert diese nacheinander mit dem obigen Flow.
Die erste Datei enthält z.B. 3 Zeilen. In der zweiten Datei entfernt man einfach eine Zeile.
Erwartetes Ergebnis:
In der 1. Ausführung werden 3 Zeilen importiert.
In der 2. Ausführung werden nur 2 Zeilen importiert. Der Datensatz der entfernten Zeile befindet sich jedoch noch im Datastore von der 1. Ausführung, wurde aber auf Stock 0 gesetzt
Mehrere Lieferanten im Datastore
Der oben beschriebene Prozess setzt voraus, dass der Datastore ausschließlich Artikel eines einzigen Lieferanten beinhaltet.
Sollten Sie mehrere Lieferanten im gleichen Datastore verwalten, dann sollte man pro Lieferant einen extra Folder benutzen. In diesem Fall sollten sie die Erweiterte Option untouchedRecordsMode des SpreadsheetDatastoreWriter Steps (Step 4) auf Affected folders stellen.
Fehler abfangen
Was passiert, wenn die Daten des Lieferanten spontan unvollständig sind? (z.B. durch einen Übertragungsfehler oder Verbindungsabbruch)
Das ist eine berechtigte Frage bei diesem Ansatz. Es ist vorstellbar, dass eine CSV-Datei beim Abruf leer oder unvollständig ist oder eine API plötzlich keine Artikel liefert, obwohl welche kommen müssten. In beiden Fällen sieht es dann so aus, als würden Artikel nicht mitkommen. Die folge wäre, dass die Logik dann ggf. alle Artikel auf Bestand=0 setzt. Das wäre schlecht.
Lösungsansatz
Ein Möglichkeit wäre z.B. die Dateigröße zu prüfen und den Flow mit einem StopFlowIF-Step zu stoppen, wenn eine bestimmte Mindestanzahl Artikel nicht mit kommt oder die Datei eine Mindestgröße unterschreitet.
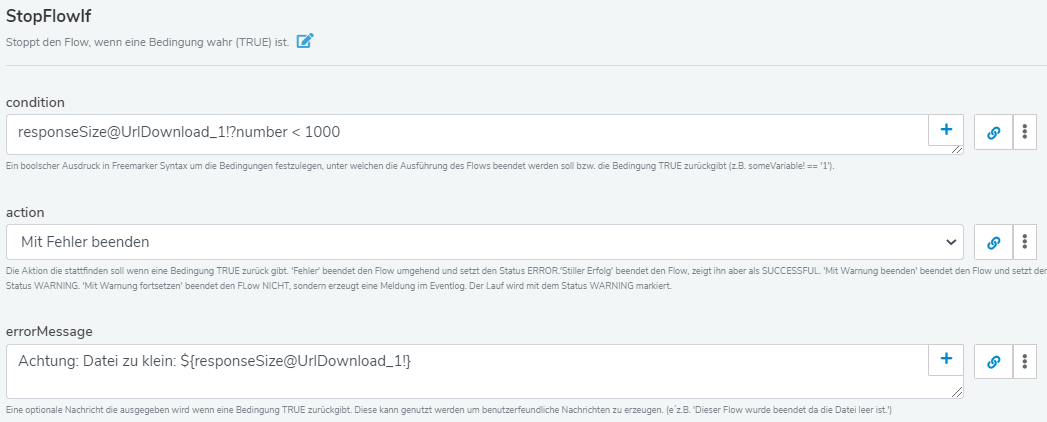
Dieser Ansatz ist zwar nicht perfekt, aber er fängt die schlimmsten Fälle ab, um nicht das komplette Sortiment zu nullen. Der Ansatz setzt voraus, dass man z.B. die Mindestdateigröße grob weiß. D.h. wenn eine Artikel.CSV Datei immer mindestens 1MB groß ist, dann sollte man den Flow lieber abbrechen, wenn die Datei kleiner ist.
Man kann sich über den Fehler informieren lassen und dann immer noch manuell prüfen und den Flow erneut starten.