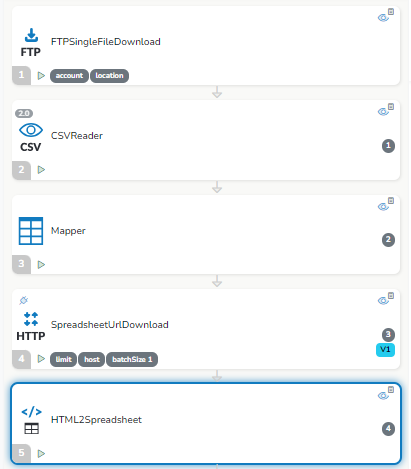
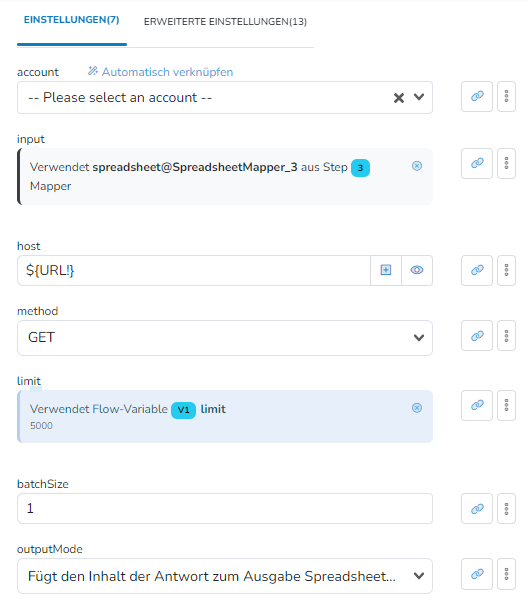
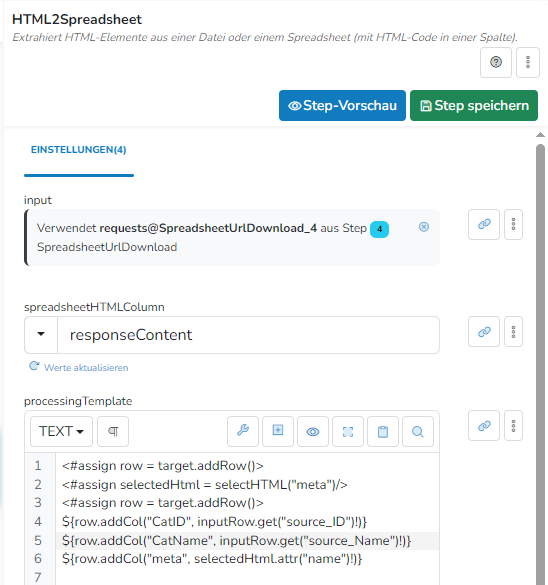
Nach meinem Verständnis müsste ich jetzt eine Auflistung aller Meta-Tags mit ihrem Name erhalten, oder?
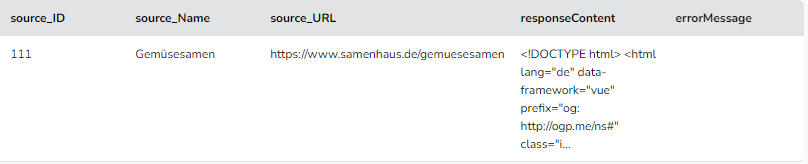
Ich bekomme aber nur eine Zeile raus, mit einem Meta-Tag
Der Meta-Viewport steht ein paar hundert Zeilen weiter oben als der Robots, kanns daran liegen? Ich dachte dass vllt abgeschnitten wird weil ich in irgend ein Limit laufe, aber wenn ich mir die response_1.txt runter lade, dann ist da alles drin?
Dann selektiere ich falsch?
Was mach ich falsch?
Test-URL ist https://www.samenhaus.de/gemuesesamen
Ich hatte mich am Handbuch orientiert, da ist auch keine Schleife drum, und da steht
Das processingTemplate wird für jede Zeile des Input-Spreadsheets angewendet, um daraus HTML-Elemente zu extrahieren.
und weiter unten
Das Skript wird auf jedes Eingabeelement angewendet (z. B. auf jede Zeile eines SPREADSHEET).
Hatte ich so verstanden, dass das von alleine über alle Zeilen loopt. Jetzt seh ich: es geht nicht um die Zeilen im responseContent, sondern um die im Spreadsheet
Wie müsste so eine Schleife dann aussehen, um über alle von selectHTML gematchten Elemente zu iterieren? Steh grade auf dem Schlauch…
Alternativ: mit einem Suchterm fürs selectHTML dass mir direkt nur den Robots Metatag selektiert, würde sich mir das Problem gar nicht erst stellen