Hallo Team,
um Bug Hunting sinnvoll betreiben zu können, bin ich auf die Vorschaudaten angewiesen. Ich habe jetzt schon ein Zwischenergebnis als Exceldatei speichern und auf den Server laden lassen, weil das alles nicht funktioniert (NICHT aus der Vorschau heraus, ich habe dafür den Flow mit vielen deaktivierten Gruppen und extra gesetzten Verknüpfungen in einem Sonderrun laufen lassen). Nun lasse ich die Excel importieren und als neue Quelle für die folgende Auswertung nutzen. Aber es klappt trotzdem nicht:
Mapper auf den Excel-Reader:
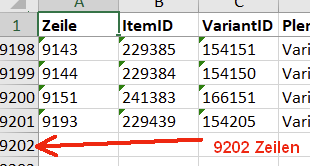
10000 Zeilen angezeigt, Suche nach…
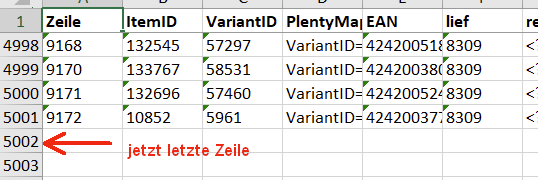
Treffer in der 6475. Zeile, man beachte die „7338“ in der letzten Spalte
Soweit diese Vorschau. Nun in den folgenden Filter:
Folgender Mapper
Komplett aufgezogen, nur 210 Zeilen werden angezeigt. Suche nach 7338 ergibt auch 210
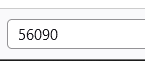
Suche nach 56090 ist erfolglos.
Ich habe schon beim Mapper und beim Filter den Cache aktiviert. hilft alles nichts. Warum sehe ich im Mapper nach dem Filter nur teilweise Daten?
Ich habe eben noch einen ExcelWriter und einen FTPUpload auf diesen Step gesetzt zzgl. einen anschließenden Stop-Flow, damit er da aufhört, und den Flow laufen lassen. Wie erwartet het die Datei alle 7338er Einträge, die der Mapper nach dem Filter auch hätte anzeigen müssen, es aber nicht tut:
Bitte schafft hier möglichst schnell Abhilfe oder sagt mir, was ich da falsch mache. Um’s mit Heinz Schenk zu sagen: Isch kann so net abbeide!
Danke und Gruß,
Micha
podcomm e-commerce management
nur um erst Einmal den trivialsten Fehler auszuschließen, der mir einfällt. Kannst du in der Filterbedingung noch ein ?trim an die SupplierID! setzen? Ich bezweifle zwar, dass das etwas bringt, da du dir ja das Filterergebnis auch nochmal als Datei zuschicken lässt.
Alternativ kannst du uns auch gern die Datei als Ticket zuschicken, dann werden wir dass einmal genauer checken.
EDIT: Neben Leerzeichen können es natürlich auch Steuerzeichen sein.
Und Du schreibst ja selbst: Wenn ich den Flow laufen lasse, werden die Werte ja ermittelt - also kann m.E. im Flow selbst ja kein Fehler vorliegen. Ich weiß nicht, was ich da noch machen kann. Ggf. werde ich den Flow in meinem Entwickleraccount aufsetzen und euch dann Zugang geben, sofern ich dazu mal Zeit habe…
Ich habe hier noch einen ganz anderen Fall. Mittlerweile bin ich sicher, daß euer Filter-Step nicht funktioniert bzw. ein hard cap bei 5000 Zeilen hat - übrigens egal ob man den Filter bypasst oder nicht. Folgendes:
Mapper
→
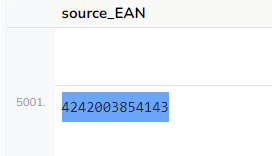
Ihr müßt irgendwo ein cap bei 5000 Zeilen drin haben!! Ich habe hier einen Mapper, den ich danach mit einem anderen appende. In beiden ist die Zeile mit der Spalte source_EAN=4242003854143 drin. Im zweiten Mapper dieser append-Combo (VOR dem append-Step) sehe ich
Wieder diese Mist-5001ste Zeile. Die hat in Spalte „statusCode“ eine 300, wie man im Screenshot sieht.
Jetzt der erste Mapper:
Jetzt der Append-Step:
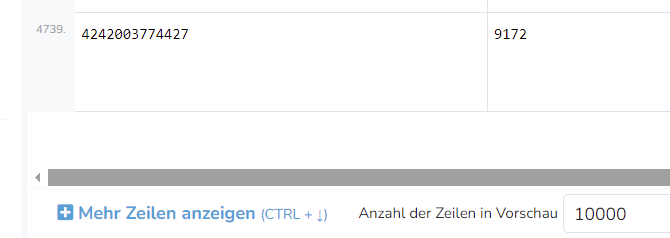
Das sah in einem anderen Browser vorhin noch anders aus, da waren es tatsächlich 8452 Zeilen, aber bei „Error“ stand nichts drin. Er hatte also wieder die Info aus dem zweiten Mapper nicht angezeigt. Bevor Du fragst: Ja, die Spalten aus dem zweiten Mapper sind im Mapper nach dem append auf „Wert der letzten Zeile“ eingestellt. Also: Entweder zeigt er nur rund die Hälfte der Zeilen (im einen Browser), oder er zeigt alle Zeilen, aber zeigt nicht die korrekten Werte der Aggregierung an. Das ist insgesamt sehr schlecht.
Nachtrag: Ich sehe gerade, daß wenn ich die Daten direkt aus dem ExcelReader hole, er alle Zeilen anzeigt (aber wie gesagt nicht mit dem Aggregierunsergebnis des zweiten Mappers). Lasse ich die Excel-Daten erst in einen Mapper fließen (ohne die Daten zu ändern) und referenziere dann den Mapper, zeigt das Ergebnis nur 4752 Zeilen an.
entschuldigung, dass wir dich solang im dunkeln gelassen haben, aber du hast recht. Wir haben ein Limit im Cashe-Mode in der Vorschau von 5000. Das ganze hat einen technischen Hintergrund und ist in der Flowausführung natürlich nicht vorhanden.
Zusätzlich kann ich dir noch den StoreDebugFile Step empfehlen. Mit diesem kannst du deine erstellte Datei temporär in Synesty hochladen und kannst diese dann aus dem Eventlog hochladen. Dann musst du dir die Datei nicht auf einen FTP hochladen.