Hi zusammen,
ich bin mal wieder dabei, unsere Synesty-Kosten zu optimieren.
Ich war dann recht überrascht davon, dass unser teuerster Flow einer ist, der nur einen PlentyGetVariations mit allen Parametern abfeuert, und in einen Datastore schreibt.
Der macht 700MB Traffic pro Durchlauf, und läuft mehrmals täglich:
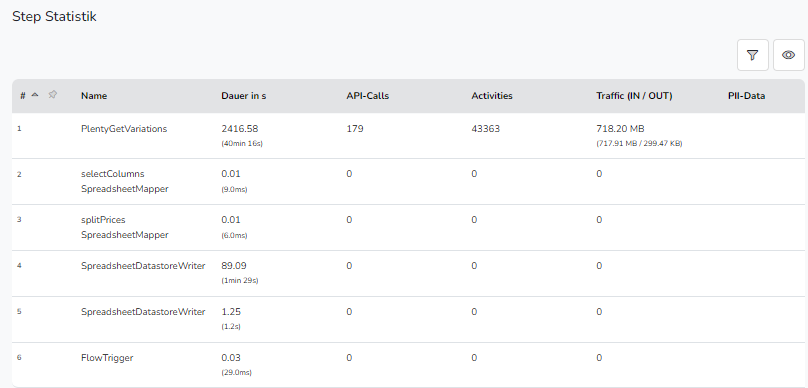
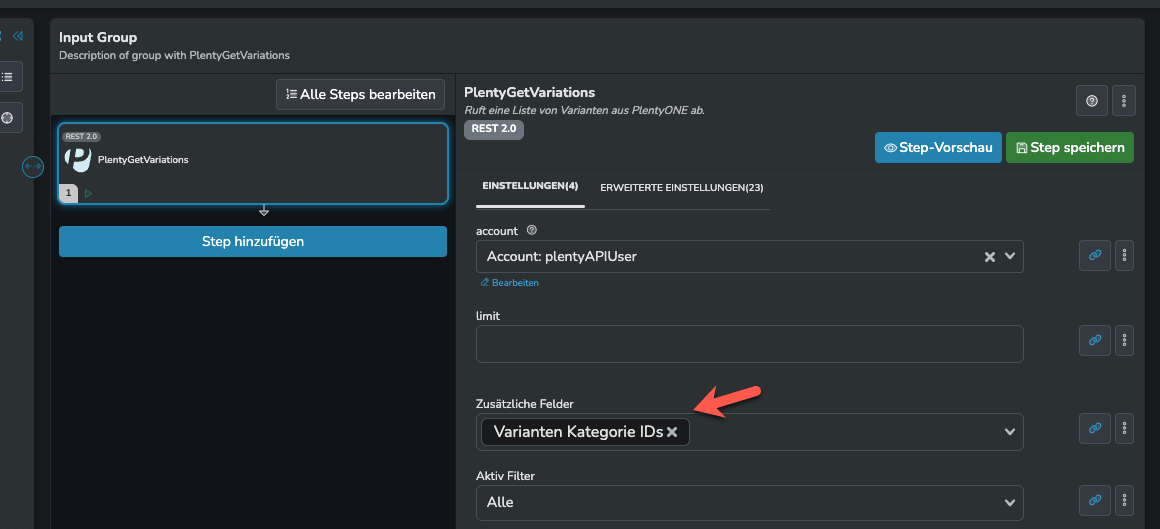
Da sind alle „zusätzlichen Felder“ aktiv, außer Artikelbilder. Abruf ergibt ca 43.000 Varianten.
Was mich jetzt stutzig gemacht hat: der verursacht so viel Traffic, aber wenn ich den Datastore exportiere in den ich alles schreibe, hat der nur 320 MB.
CSV, also plaintext, unkomprimiert. Wenn ich das wiederum gzippe, kommen ich auf 31 MB. Bisschen Overhead ist natürlich immer, aber so krass kann ich mir kaum vorstellen.
Umgekehrt gibts aber auch nur wenige Spalten aus dem Call, die ich zwar abrufe, aber nicht speichere:
klick
IsMain
CustomsTariffNumber
PropertiesInherited
TagsInherited
ParentVariationID
ItemPropertiesJSON
ItemPropertiesWithGroupsJSON
AvailabilityUpdatedAt
AdditionalSkuUpdatedAt
BarcodeUpdatedAt
BundleComponentUpdatedAt
CategoryUpdatedAt
ClientUpdatedAt
DefaultCategoryUpdatedAt
ImageUpdatedAt
MarketUpdatedAt
MarketIdentNumberUpdatedAt
SalesPriceUpdatedAt
SkuUpdatedAt
SupplierUpdatedAt
PropertyUpdatedAt
WarehouseUpdatedAt
TagUpdatedAt
CommentUpdatedAt
VariationAccountMarketSkus
VariationPropertiesJSON
Die Spalten für ItemProperties und VariationProperties sind sicher recht lang (und werden dann verworfen), aber auch die sollten ja mit gzip egtl gut komprimieren. Kurzum: ich würde egtl viel weniger Traffic erwarten für diesen Abruf.
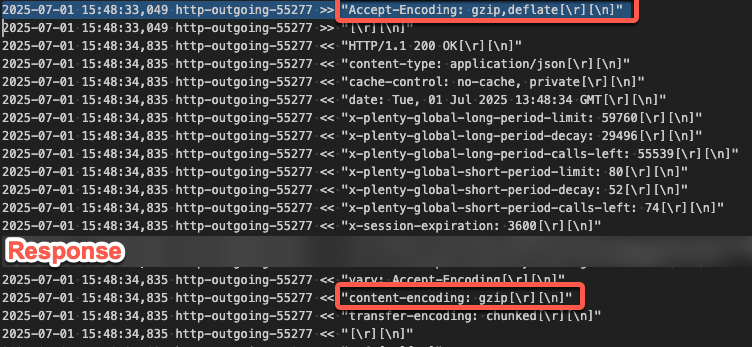
Könnt ihr das mal prüfen, ob hier unkomprimiert übertragen wird?
Die API von Plenty kann auf jeden Fall content-encoding gzip, das habe ich grade mal mit Postmann geprüft. Aber wirds auch genutzt?
Ich hab grade mal einen Durchlauf mit Debug-Log durchgeführt, runID ist 0197c275-cdf1-7ef6-9b8f-78a21a0a7c85, Flow heißt SH_getItemData_REST. Rein schauen kann ich aber selbst nicht mehr…
Danke im Voraus, Daniel