Hallo zusammen,
aktuell haben wir folgendes Problem.
Zuerst zum Kontext:
GLS hat vor kurzem auf ihre Document Management und Customs V3 API umgestellt. Zunächst holen wir uns über einen POST Call eine documentID, upload_URL und download_URL. Im nächsten API Call laden wir die Dokumente dann per PUT an die angegebene upload_URL hoch.
Die Dokumente bekommen wir über den Stepp „PlentyGetOrderDocuments“ und hängen diese per ${meta.documentFiles@PlentyGetOrderDocuments_2!} direkt an den PUT Call an.
Das Problem ist dass auf dem S3 Server die Datei leer hochgeladen wird. Hier wissen wir nicht genau warum. Wenn wir hinter „PlentyGetOrderDocuments“ noch einen FTP Upload hängen und die Dokumente darauf hochladen, können wir sie öffnen da diese „ganz“ übertragen werden.
Geschickt werden die Calls über den Stepp „SpreadsheetUrlDownload“.
Gibt es hier die Möglichkeit gezielt das Encoding auf binary zu setzen ? Aktuell haben wir die Vermutung dass aufgrund einer falschen Enkodierung der S3 Server die Datei zwar akzeptiert, den Inhalt aber nicht erkennt / überträgt.
Viele Grüße
Oliver
Hallo @eRocket-Oliver_Widrinski,
du könntest mal versuchen den BodyContentType auf multipart/form-data; charset=ISO-8859-1 zu setzen und/oder als requestHeaders Content-Transfer-Encoding="BINARY" zu benutzen.
Viele Grüße
Lukas
Hallo @synesty-Lukas,
ich hatte es jetzt mal so angepasst:
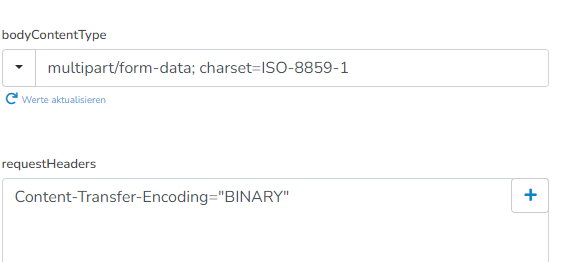
Leider hat auch das nicht funktioniert. Zwar habe ich, als ich das Dokument runterladen wollte, eine Rückmeldung vom Endpoint bekommen, das Dokument ist aber weiterhin leer.
Hallo Oliver,
In welchem Feld hast du das ${meta.documentFiles@PlentyGetOrderDocuments_2!} ?
Das wird wahrscheinlich nicht funktionieren. Die Dateien müssten mit dem fileToUpload
verknüpft werden.
Viele Grüße
Torsten
Hallo @synesty-Torsten ,
${meta.documentFiles@PlentyGetOrderDocuments_2!}
stand ursprünglich im requestBody der Anfrage mit drinnen. Das habe ich jetzt mal durch den Einsatz des Felds filtToUpload ersetzt und mit den Ergänzung von Lukas erweitert.
Leider hat auch das nicht funktioniert.
Würde es euch ggf. helfen wenn ihr ich euch den Log der Ausführung zukommen lassen würde ?
Viele Grüße
Oliver
Hallo Oliver,
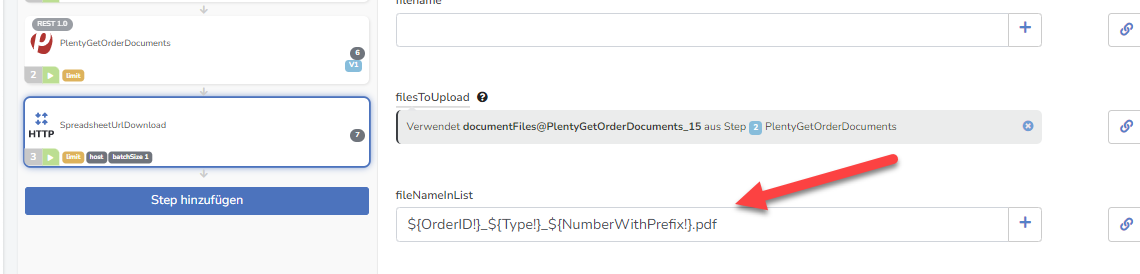
eine wichtige Einstellung hatte ich vorhin nicht erwähnt. Im Feld fileNameInList muss noch der Name der Datei rein, die hochgeladen werden soll.
Wenn du als Input das Output Spreadsheet des PlentyGetOrderDocuments Steps verwendest, kannst du in fileNameInList den Wert ${OrderID!}_${Type!}_${NumberWithPrefix!}.pdf verwenden.
Falls das nicht hilft kannst du uns gerne den Debug Log von der Flow Ausführung (per Ticket) schicken.
Viele Grüße
Torsten
Guten Morgen @synesty-Torsten ,
der Vorschlag von dir passt soweit. Es gibt jedoch noch ein Problem.
In deinem Beispiel nimmst du ja bei „fileNameList“ direkt den Input aus dem „PlentyGetOrderDocuments“ Stepp. Jedoch brauche ich bei „input“ einen anderen Stepp. Dieser ist ein Mapper der aber auch das FileName bereits enthält. Im Vergleich zu den Metadaten der aus dem „PlentyGetOrderDocuments“ ist der Name identisch.
Als Beispiel:
Im Mapper steht bei „FileName“ 5069372_pro_forma_invoice_PR23-937.

Wenn ich mir über einen TextHTMLWriter die Metadaten von dem Dokument hole, ist der Name identisch. Hier ist der Name im Mapper:

Wenn ich den API Call aber ausführen möchte, kommt folgende Fehlermeldung:
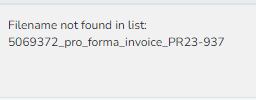
Als Test hatte ich bereits dem Namen fest in das Feld „fileNameList“ reingeschrieben. Der Call ist auch für das Dokument durchgegangen und wurde mit dem Status 200 zurückgegeben.
Viele Grüße
Oliver
Hallo Oliver,
ich glaube da fehlt noch ein „.pdf“ am Ende des FileNames.
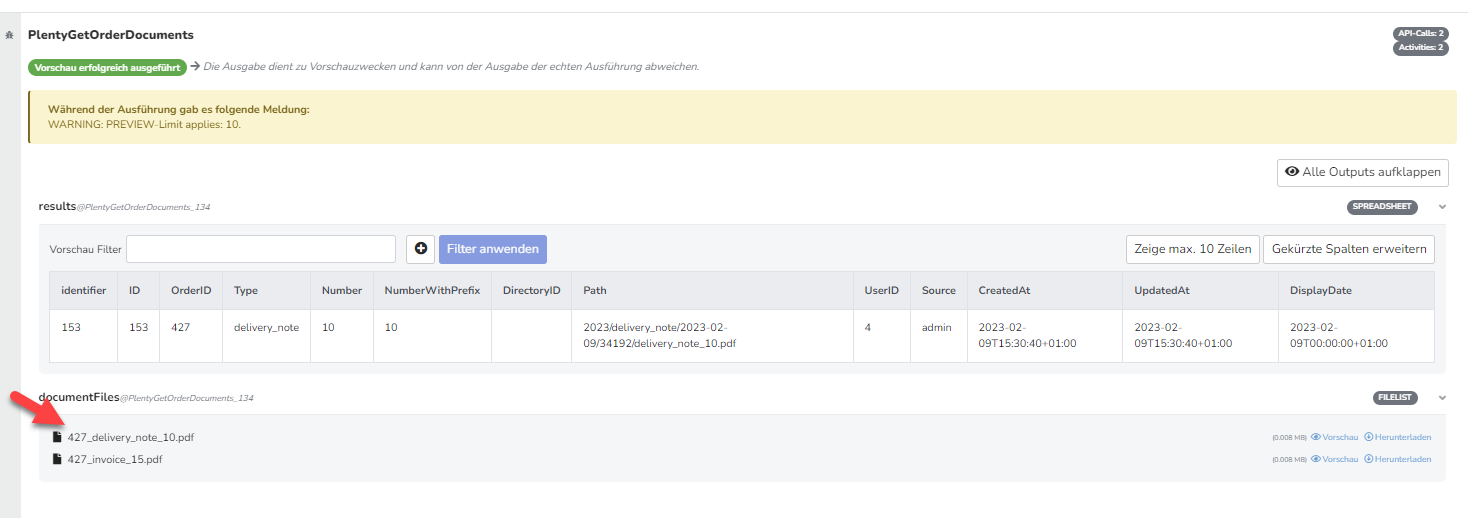
In fileNameInList muss immer der vollständige Dateiname aus der filesToUpload Liste angegeben werden. Die Dateinamen findest du in der Vorschau des PlentyGetOrderDocuments Steps:
Viele Grüße
Torsten
Hallo @synesty-Torsten ,
habe es jetzt hinbekommen  .
.
Ich habe einiges ausprobiert, aber im Endeffekt hat folgendes probiert.
Hinter dem Mapper, den ich als Input brauche, habe ich ein SpreadsheetAppend eingefügt. Dieser fügt den besagten Mapper und das Ergebnis des PlentyGetOrderDocuments Steps zusammen und wird anschließend auf die OrderID gruppiert.
So konnte ich dann in fileNameList ${OrderID!}_${Type!}_${NumberWithPrefix!}.pdf einpflegen.
Alles andere hat nicht funktioniert.
Also vielen Dank für die Hilfe.
Viele Grüße und schon mal ein schönes Wochende
Oliver