es fällt mir immer wieder auf die Füße, daß man in einem XML- oder JSON-Parser keine Variablen verwenden kann. Das führt bei mir in einem Fall zu Fehlern. Ich habe ein riesiges XML, in dem für jeden Artikel x ‚attributes‘-Segmente stehen - die muß ich einlesen. In einem späteren Step, der diese Daten verarbeitet, kommt es zum Fehler, daß das Quell-Spreadsheet mehr als 500 Spalten hat. Ich sehe aber keine Möglichkeit, das zu verhindern, da ich ja keine Variable setzen kann. Mein Vorhaben wäre, daß ich bei jedem row.addCol- Vorkommen in der list-Anweisung im Parser überprüfe, ob noch Platz für weitere Spalten ist. Das würde ich normalerweise so lösen (Anm.: „ind“ ist eine Flowvariable mit dem Wert 400):
…
<#assign row = target.addRow()>
${setVariable(‚ind2‘, 0)}
…
<#list book[„attributes“][„attribute“] as attr>
…
<#if ind2 lt ind!?number>
${setVariable(‚ind2‘, getVariable('ind2)+1)}
${row.addCol("TD "+altattr+alta, vars)}
…
Damit würde das letzte Attribut in eine Spalte geschrieben, wenn das 400. verschiedene -Segment erreicht wäre - der Rest würde dann ignoriert.
Ich sehe keine andere Lösung für dieses Problem, als mit dieser Variablen zu arbeiten (abgesehen von unprofessionellen Lösungen wie dem teilweisen Hereinladen in einen folgenden Mapper, bis die max. Anzahl an Spalten erreicht ist, und diese Mapper-Konfiguration dann fix zu lassen. Das wäre die unsauberste Lösung). Wenn ich statt setVariable mit assign arbeite und dieses hochzählen lasse, vergißt er bei jedem nächsten -Segment diesen Wert und fängt wieder bei Null an.
Könnt ihr uns dafür nicht irgendwas bereitstellen? Mir reicht ja irgendein Index, der meinetwegen nach dem Hinzufügen einer neuen Spalte hochgezählt wird.
Wenn du das statt der hart-codierten 400 über eine Flow-Variable steuern möchtest, dann kannst du z.B. eine Flow-Variable „spaltenlimit“ anlegen und auch jetzt schon darauf zugreifen:
Übrigens brauchst du nicht lt / gt für größer/kleiner als in den IF-Anweisungen.
Umschließe den Ausdruck einfach komplett in Klammern, und schon meckert Freemarker nicht mehr
Edit: das eine S bei row.getSpreadSheet() muss groß sein (war beim ersten Wurf noch klein geschrieben)
Ich muß leider zurückrudern. Klappt doch nicht richtig. Ich parse das File exakt in der Reihenfolge der jeweiligen Nodes. Beim Segment der attributes ermittle ich die zu diesem Zeitpunkt erreichte Spaltenanzahl mittels
<#assign b = row.getSpreadSheet().getNumberHeaderCols()?string>
und schreibe den Wert in eine extra Spalte
${row.addCol(SpalteNr, b)}|
Im Ergebnis steht beim ersten Artikel zunächst die korrekte Zahl drin (27). Das geht dann so weiter bis Zeile 15 (87). In Zeile 16 steht dann plötzlich 29! Dann geht es (gemessen an dem falschen Ausgangswert von 29) korrekt weiter bis Zeile 23 (59). In Zeile 24 steht dann plötzlich wieder 29. Usw. usf. Ich sage gleich, daß in dem Mapper keinerlei Sortierung aktiviert ist, die das Ergebnis verfälschen könnte. das ist doch alles Mist, so kann man hier nicht weiterkommen, ich brauche die Möglichkeit der Variable.
OK danke das hilft bei der Suche. Hilfreich wäre noch, wenn du uns einen kleinen Auszug deiner XML zur Verfügung stellen könntest. 2 Artikel mit jeweils unterschiedlicher Anzahl Attributen würde reichen.
vielen Dank für die Beispieldatei. Eine Möglichkeit die Gesamtanzahl der Spalten XML Datei übergreifend im XMLReader Step zu zählen, wäre eine Flow Variable vom Typ Counter. Beim Counter kannst du pro Spaltentitel einen Zählwert einfügen. Wenn die Anzahl der Zählwerte größer als 400 ist, dann werden die Spalten nicht mehr hinzugefügt.
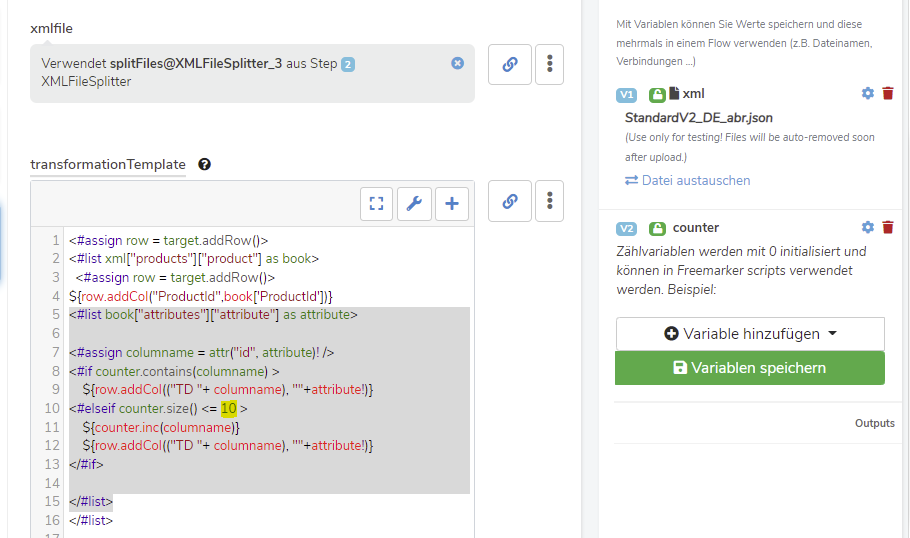
so ganz begreife ich den Code nicht. Okay, counter ist eine Zählvariable. columname scheint der Eintrag im „id“-Feld eines Attributs zu sein, jedenfalls ein String (z.B. „ATT_Grundfarbe“). Was heißt denn dann „<#if counter.contains(columname)>“? Wenn eine Zahl einen String beinhaltet? Verstehe ich leider nicht.
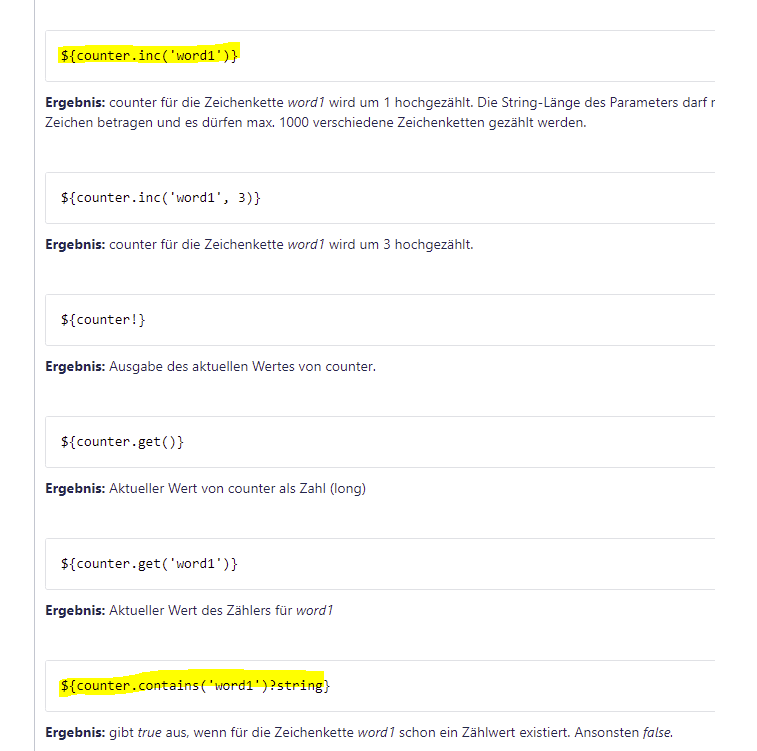
counter ist der Name meine Flowvariable vom Typ Counter. Eine Counter Flowvariable kann verwendet werden, um für verschiedene Werte (bis zu 1000 verschieden Zeichenketten bzw. Keys) hochzuzählen (counter.inc("wert")). Außerdem kann über counter.contains("wert")geprüft werden, ob schon ein Zählwert für einen Key existiert.
Die contains Funktion des Counters verwende ich im Skript um zu prüfen, ob für einen Spaltename schon ein Zählwert existiert. Falls ja kann dieser Wert hinzugefügt werden, da die Spalte im Ergebnis Spreadsheet schon vorhanden ist.
Falls der Spaltenname noch nicht hinzugefügt wurde, prüfe ich ob schon mehr als 400 unterschiedliche Spalten (Zählwerte im Counter) hinzugefügt wurden (counter.size() <= 400).
Wenn das nicht der Fall ist wird für den Spaltenname eine neuer Zählwert erstellt bzw. hochgezählt (counter.inc(columname)) und der Wert im Ergebnis Spreadsheet hinzugefügt.
Das „id“-Feld hab ich nur zum testen verwendet, da ich nicht genau wusste woher die Werte altattr und alta bei dir kommen. Bei dir müsste der assign Block für den Spaltennamen vermutlich so aussehen:
 ,
,