ich habe hier eine sehr große XML-Datei, die mir in ihrer Größe zu schaffen macht. Wenn ich alles einlese und sie dann gegen eine importierte Datei „halte“, um neue Artikel zu ermitteln, komme ich an eine Grenze:
Ich muß also vor dem Parsen bereits die schon vorhandenen rausschmeißen. Ich habe dafür ein bißchen mit Arrays experimentiert, und alles schien perfekt zu funktionieren:
.Ich habe eine kommaseparierte Liste von schon vorhandenen IDs
→ Beispiel: 516951,516964,516950,516960,516961,386020,386022,516935,516936,516945
.Die lese ich am Anfang des XML-Parsers in ein Array ein
–><#assign nope = ><#list spreadsheet@SpreadsheetMapper_1106.firstRow(„AlltronProductID“)?split(‚,‘) as np><#assign nope += [np]></#list>
.Dann kommt die erste <#list>-Anweisung
–><#list xml[„products“][„product“] as book>
.In dieser lese ich die ID der jeweiligen Zeile in eine Variable ein
–><#assign pid = book[„ProductId“]>
.Dann überprüfe ich, ob die ID im Array vorkommt- nur wenn nicht, soll das Element geparst werden
–><#if !nope?seq_contains(pid!)>
usw.
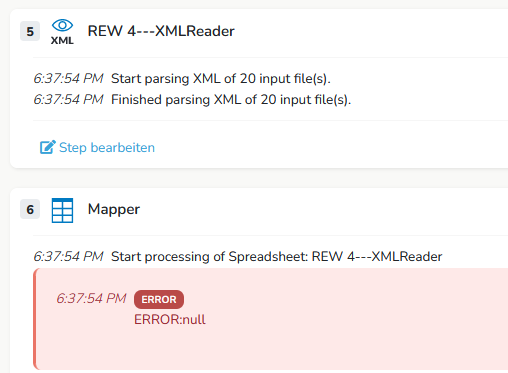
Wenn ich das so mache, werden die nicht gewollten ausgelassen - soweit, so gut. Nun sind das aber nicht nur zehn Stück, sondern über 200.000. Die lese ich aus einer Spalte eines Datastores ein und aggregiere sie, so daß sie in einer Spalte kommasepariert vorliegen. Wenn ich den Flow nun laufen lasse, bekomme ich folgendes:
Error ‚null‘
Was ist das? Heißt das , daß das Array vielleicht zu groß ist?
Ich weiß natürlich, daß ich das Problem auch über einen Querverweis zum Datastore lösen kann, dann würde er aber erstmal alle Artikel einlesen und müßte den QV danach auf mehrere hunderttausend Zeilen anwenden - es wäre also sinnvoll, wenn das mit meiner Methode funktionieren würde - oder gerne auch anders, ioch freue mich auf andere Ideen
200.000 Einträge sind hier zu viel. Aber so wie du es vorgeschlagen hast, wäre hier der Querverweis auf den Datastore die beste Möglichkeit. Die XML muss ja sowieso geparst werden, da kannst das auch nutzen um den QV auf den Datastore zu machen.
das lässt sich pauschal nicht beantworten und hängt von einigen Faktoren ab, u.a. auch vom bisherigen Flow. Der Fehler „null“ hat aber wahrscheinlich nichts mit der Array Größe zu tun. Es deutet darauf hin das eine Variable nicht vorhanden ist oder ein andere Fehler im Step auftritt.
Ich vermute die Ursache liegt irgendwo bei spreadsheet@SpreadsheetMapper_1106.firstRow("AlltronProductID")?split(",").
Diesen Teil würde ich auf keinen Fall im XMLReader Step machen, vor allem nicht wenn mehrere XML Dateien verarbeitet werden. Das template des XMLReaders wird pro XML Datei 1x ausgeführt. D.h. der Teil wird auch 20x ausgeführt, wenn du 20 input files im XMLReader verwendest. Das Ergebnis des Mappers wird dann wegen der lazy Ausführung ggf. auch 20x neu geholt. Das kann sehr aufwendig werden, wenn du z.B. 200.000 Zeilen in diesem Mapper gruppierst.
Bemerkung nebenbei
Das spreadsheet@SpreadsheetMapper_1106.firstRow(„AlltronProductID“)?split(",") könntest du direkt zuweisen. Die zusätzliche #list Anweisung ist eigentlich nicht notwendig:
Warum genau willst du die Produkte im XMLReader rausfiltern und nicht mit Querverweis und Filter Step? Diese Steps sind für die zeilenweise Abarbeitung optimiert und der QV sollte dir genau das liefern, was du versuchst in Freemarker nachzubauen. Bei der Datenmenge solltest du auf Arrays oder Maps zu im Speicher verzichten, selbst wenn es jetzt funktioniert. Wenn in 2 Monaten nochmal X Produkte dazu kommen und es dann zu viel wird, musst du den ganzen Flow umbauen.
danke für Deinen Input. Im Moment habe ich das auch über einen QV gelöst - solange dieser Datastore einen größeren Sinn hat als nur die rauszufilternden ProductIDs zu beinhalten, ist das auch sinnvoll so. Wenn mein Klient aber meint, daß er keine Lust hat, NUR wegen dieser Information den Datastore vorzuhalten und dafür ständig teure Datenzeilen nachbuchen muß, könnte er auf die Idee kommen, daß ich am Flowanfang lieber eine Excel importieren soll, wo zu jeder VariantID eben diese PID steht. Dann müßte ich diese PIDs in das Array einlesen und gegen die PIDs der XML filtern. Ich befürchte, daß es über kurz oder lang darauf hinauslaufen wird.
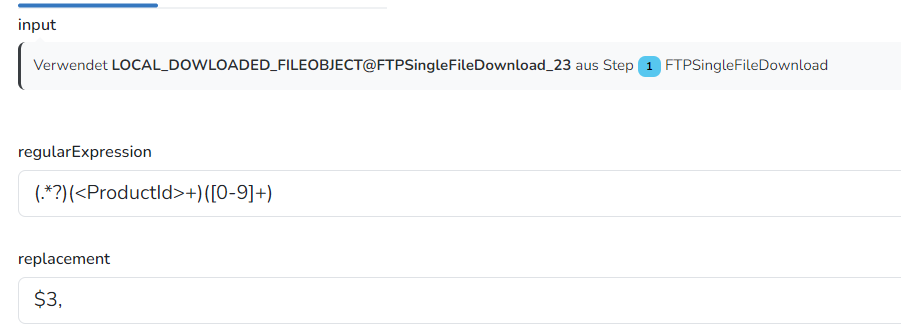
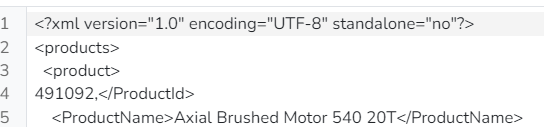
Mir fiel noch eine andere Möglichkeit ein - ich könnte das Array auch herstellen, indem ich die XML durch mehrere FileFindAndReplace-Steps jage, bis nur noch die PIDs kommasepariert übrigbleiben. Aber leider funktioniert die Regex da irgendwie nicht, kannst Du mir da mal bitte helfen? Im Anhang eine grob verkleinerte XML. In Notepad++ komme ich da mit zwei Ersetzungen ans Ziel (beide mit aktiviertem „matches_newline“):
Mist, ich kann die XML nicht hochladen, das Format ist nicht erlaubt. Ich probiere mal die Endung .txt, das müßtest Du dann bitte wieder nach XML ändern.
Maaaann, txt wird auch abgeschmettert. Dann json Test2.json (39,0 KB)
ok, so richtig verstanden habe ich es noch nicht. Sollten die ProductId aus der XML nicht mit vorhandenen Datensätzen (im Datastore) abgeglichen werden ?
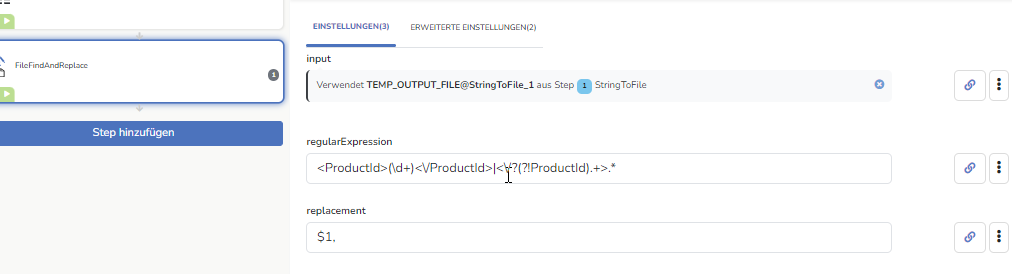
„matches_newline“ funktioniert mit dem Step nicht. Suchen & ersetzen wird immer pro Zeile ausgeführt.
Mit folgenden Einstellungen solltest du aber schon ein einigermaßen gutes Ergebnis bekommen:
Das könntest du z.B. mit dem CSVReader einlesen und mit einem Filter Step die Zeilen mit leerem Wert entfernen, sodass du am Ende ein Spreadsheet mit den ProductIds hast.