Hallo zusammen,
wie schon grade in der Sprechstunde erwähnt, würde ich mich über einen Schritt freuen, welche die Daten von zwei Spreadsheets vereint.
Der Schritt soll es ermöglichen, die Daten aus einem Spreadsheet mit übergeordneten Daten (z.B. OrderHeader) an alle zugehörigen Zeilen aus einem Spreadsheet mit untergeordneten Daten (z.B. Bestellpostionen) weiterzugeben.
Im weiteren Verlauf werde ich die Begriff parent & child für übergeordnete bzw. untergeordnete Daten verwenden. Heißt aber nicht, dass die Daten in so eine Struktur im Datastores vorliegen.
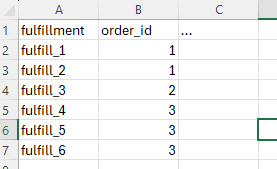
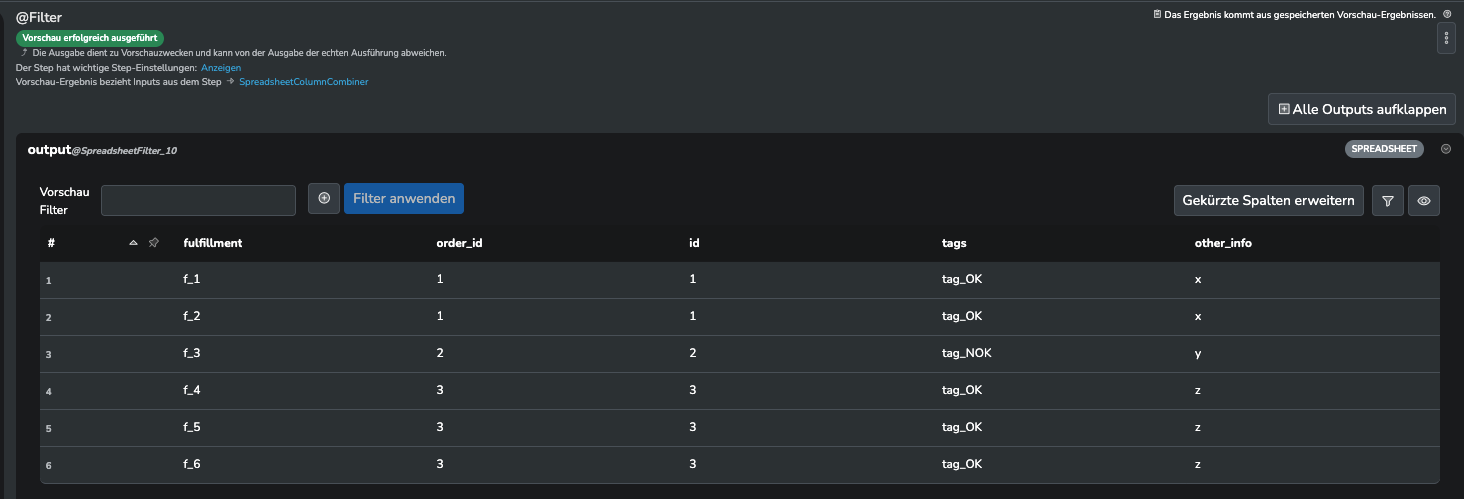
Hier erstmal ein kleines Beispiel:
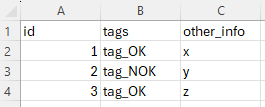
Die beiden Spalten tags & other_info aus der zweiten Tabelle sollen anhand der id-Spalte an die Zeilen mit passender order_id aus der ersten Tabelle angehangen werden:
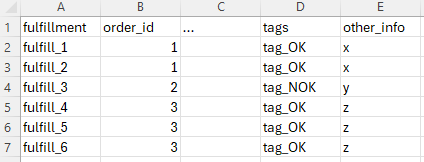
Ergebnis wäre also:
Die vorhandenen Optionen ermöglichen das leider nicht oder nur sehr begrenzt.
- Append mit anschließendem Gruppieren ist garkeine Option, da es mehrere children zu einem parent geben kann.
- KeyValueSpreadsheet erfüllen die Anforderung, jedoch nur für eine Spalte. Bei 10 Spalten brauche ich dementsprechend viele KeyValueSpreadsheet-Steps. Außerdem hat der Schritt ja ein internes Größenlimit, welches die Anwendung bei großen Tabellen unmöglich macht.
Ich habe mir dafür bereits einen eigenen Flow gebaut, der diesen Job übernimmt. Aber eine Out-of-the-box-Lösung wäre natürlich schöner. Meinem Flow übergebe ich die folgenden Inputs:
- Das zu erweiterende Spreadsheet
- Das Spreadsheet mit den zusätzlichen Daten
- Bezeichnung der Schlüsselspalte in Spreadsheet 1
- Bezeichnung der Schlüsselspalte in Spreadsheet 2 (optional, nimmt sonst die Bezeichnung aus 3)
- Zu übernehmende Spalten aus Spreadsheet 2
- Ein Prefix für die angehangenen Spalten (optional)
Im Moment benutze ich den Schritt bei den ShopifyOrders, dort übernehme ich einige Spalten vom OrderHeader an die OrderFulfillments. Das ist aber nur das aktuellste Beispiel.
Andere Anwendungen, die mir grad auf Anhieb einfallen:
- Artikel-Kennzahlen an jeder Bestellposition zu dem Artikel ergänzen
- Produktdaten aus Shopify an alle Varianten ergänzen
- Kundeninformationen an alle Bestellungen ergänzen
Lasst mich gerne wissen, wenn noch was unklar sein sollte.
Gruß
Gustav
2 „Gefällt mir“
Um das Thema nochmal ein bisschen schmackhafter zu machen:
Mein eigenen Schritt läuft 7 Minuten, um 125 Spalten auf 7 Zeilen zu kopieren. Dafür schreibt der Schritt eine Mappingkonfiguration mit knapp 850.000 Zeichen und eine Stringliste mit 125 Elementen, die ungefähr auch 850.000 Zeichen enthält.
Ich glaube, ihr könntet eine performantere Version schreiben  .
.
Hallo Gustav,
klingt nicht so toll  Vielleicht noch als Idee:
Vielleicht noch als Idee:
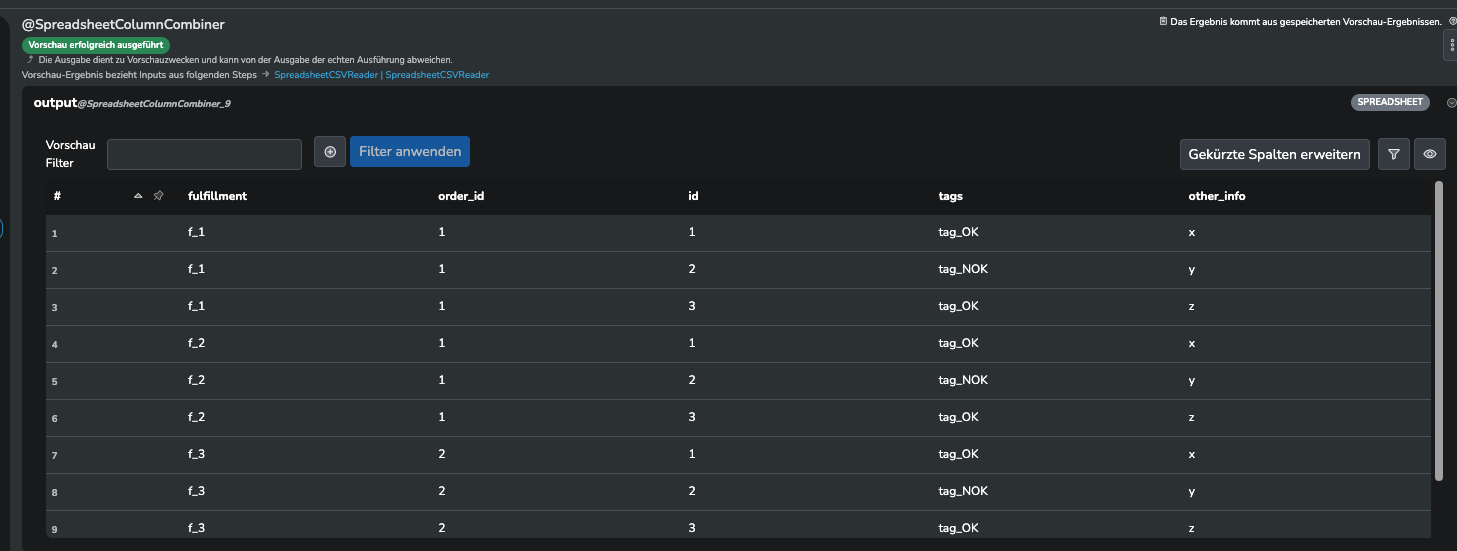
Der ColumnCombiner Step kombiniert die Spalten aus 2 input Spreadsheets. D.h. du bekommst als Ergebnis n x m Zeilen (n = Zeilen Spreadsheet1, m = Zeilen Spreadsheet2) mit allen Spalten aus beiden Spreadsheets.
Wenn du dieses Ergebnis anschließend mit einem Filter Step filterst (Bedingung Schlüsselspalte in Spreadsheet 1 == Schlüsselspalte in Spreadsheet 2) solltest du das gewünschte Ergebnis erhalten.
VG Torsten
Hallo Torsten,
erstmal danke für den Vorschlag! Das hört sich so an, als würde es das Ziel erreichen. Das wäre tatsächllich meine erste Anwendung für den ColumnCombiner.
Jedoch ist der ColumnCombiner auch ein Connector-Step. Das ist jetzt nicht wirklich attraktiv für mich, Geld dafür auszugeben, damit eure Server weniger belastet werden.
Der ColumnCombiner + Filterung ist ja auch nicht grade eine optimale Lösung. Wenn ich 1000 Auftragsköpfe mit jeweils 3 Positionen pro Auftrag vereinen, um eine Kombination von Auftragskopfdaten und Positionsdaten zu kriegen, erzeuge ich auf dem Weg 3 Millionen Zeilen, um davon dann 2997000 wieder wegzufiltern.
Gruß
Gustav
Moin Gustav,
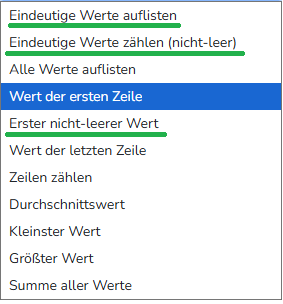
du meintest zwar „Append mit anschließendem Gruppieren ist garkeine Option, da es mehrere children zu einem parent geben kann.“ - könntest du das nicht umgehen, indem du beim Gruppieren „Alle Werte auflistest“, dann z.B. „;“ als Seperator nimmst und dann danach den MultiColumnSplitToRows verwendest und dort anhand des ; aufsplittest?
Liebe Grüße
Tim
1 „Gefällt mir“
Hallo Tim,
danke für den Hinweis! Ich habe das grade mal testweise nachgebaut und es funktioniert tatsächlich so, spitze!
Falls das nochmal für wen anderes interessant wird, hier ein Beispiel für die Konfiguration:
Gruß
Gustav
1 „Gefällt mir“
Hallo,
leider gibt es an der Lösung doch ein Problem. Es ist nicht möglich, leere Felder zu handhaben. Die Aggregatfunktion „Alle Werte auflisten“ ignoriert die leeren Werte einfach.
Wenn ich in meinem Beispiel die Namen der ersten 4 Positionen zur Bestellung 3 lösche:
Sieht es nach dem Gruppieren wie folgt aus:
Als Workaround müsste man also vorher alle Spalten mit einem Dummywert füllen und nach dem Splitten wieder entfernen.
Hat wer ne bessere Idee? Gibt es die Chance für eine neue Aggregatfunktion „Alle Werte (inklusive leere) auflisten“?
Gruß
Gustav
1 „Gefällt mir“
Hi Gustav,
stimmt - da bin ich auch schon mal drüber gestolpert - ich wusste mir dann da auch nicht besser zu behelfen, als leere Werte mit „null“ zu füllen und dies dann später wieder rauszufiltern - eine Aggregatfunktion a la „Alle Werte (inklusive leere) auflisten“, wie du meintest, wäre tatsächlich ganz schön.
Liebe Grüße
Tim
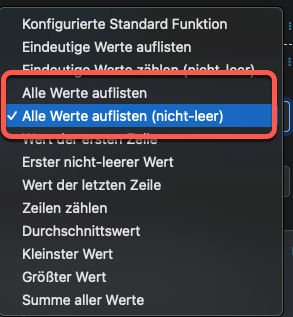
@synesty-Torsten Wäre das möglich? Um die Konsistenz in den Gruppieroptionen zu steigern, müsstet ihr eigentlich die vorhandene Option in „Alle Wert auflisten (nicht-leer)“ ändern und „Alle Werte auflisten“ als neue Option einführen.
In allen anderen Fällen erwähnt ihr explizit, wenn die Aggregatfunktion nur nicht-leere Werte verwendet, außer hier beim Werte auflisten.
Hallo Gustav,
vielen Dank für deinen Hinweis. Wir haben die Aggregatfunktionen jetzt entsprechend angepasst. Die bereits vorhanden Funktion haben wir in „Alle Werte auflisten (nicht-leer)“ umbenannt und eine neue Funktion „Alle Werte auflisten“ hinzugefügt.
VG Torsten
1 „Gefällt mir“
Hallo @synesty-Torsten,
danke für die Umsetzung. Damit sollten eure Server in Zukunft von ineffizienteren Gruppierungen verschont bleiben (zumindest durch mich)  . Man muss zwar jetzt noch die durch die leere Kopfzeile entstandenen Extrawert wieder rauswerfen, aber damit habe ich schon gerechnet.
. Man muss zwar jetzt noch die durch die leere Kopfzeile entstandenen Extrawert wieder rauswerfen, aber damit habe ich schon gerechnet.
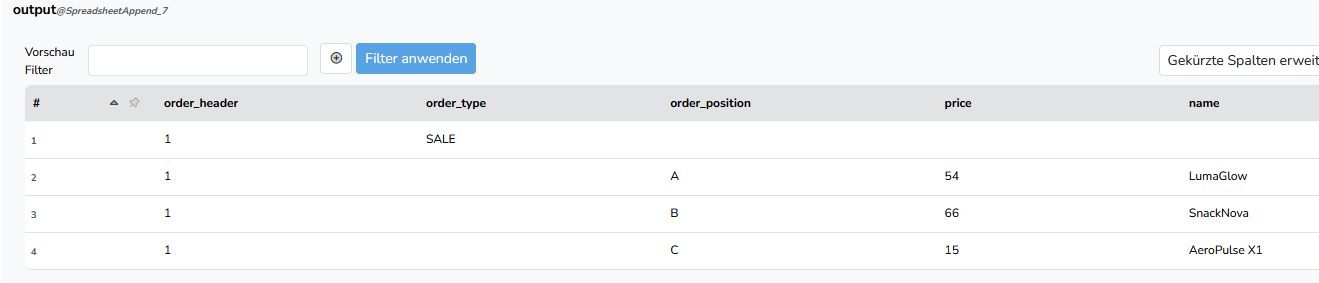
Eine Sache verstehe ich aber an der Gruppierung noch nicht so ganz. Hier ein Beispiel von meinen Eingangsdaten.
Nach dem Gruppieren mit der neuen Aggregatfunktion habe ich folgendes:
Wie kommt es dazu, dass in den Spalten der Order-Position nicht vorne überall ein Semikolon ist? Ich würde ja jetzt erwarten, dass alle gruppierten Spalten immer gleichviele Einträge haben.
Gruß
Gustav
Hallo Gustav,
Deine Erwartung ist korrekt. Bei der neuen Aggregatfunktion war noch ein Fehler vorhanden, wenn der 1. Wert leer ist. Wir haben das jetzt behoben.
VG Torsten
1 „Gefällt mir“