Hallo Zusammen,
ich habe mir einen Flow gebaut, der mir aus einem Synesty Datastore Daten über einen SpreadsheetUrlDownload Step, an die Monday.com GraphQL API überträgt. Da es ungefähr 6.000 Datensätze sind, habe ich das Ganze so aufgebaut, dass ich die Batch Size im Step entsprechend hochsetzen kann.
Mein Request Body sieht wie folgt aus:
{"query": "mutation { <#list rows as row> item${row?index}: create_item (board_id: ${meta.board_id!}, group_id: \"${meta.group_id!}\", item_name: \"${row['sku']!}\", column_values: \"{\\\"text_mks7cqvp\\\":\\\"${row['name_erp']!}\\\" ) { id } </#list> }"}
Daraus entsteht dann folgender Call
{"query": "mutation { item0: create_item (board_id: 1234567890, group_id: \"topics\", item_name: \"00002522\", column_values: \"{\\\"text_mks7cqvp\\\":\\\"Chéreau Carre Katharos 0,75l, 2022\\\") { id } item1: create_item (board_id: 1234567890, group_id: \"topics\", item_name: \"00002624\", column_values: \"{\\\"text_mks7cqvp\\\":\\\"Chéreau Carre Colere 0,75l, 2024\\\") { id } item2: create_item (board_id: 1234567890, group_id: \"topics\", item_name: \"00002623\", column_values: \"{\\\"text_mks7cqvp\\\":\\\"Chéreau Carre Colere 0,75l, 2023\\\") { id }}"}
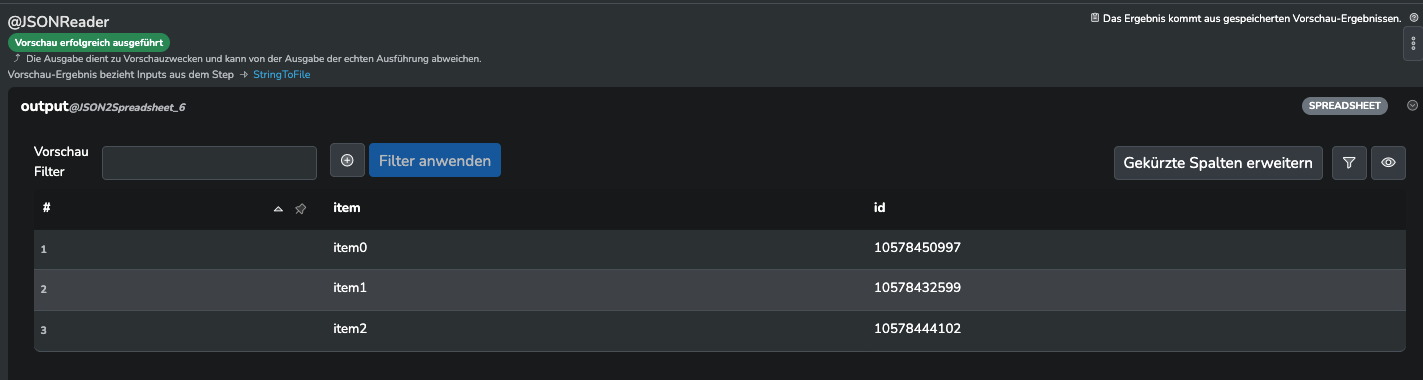
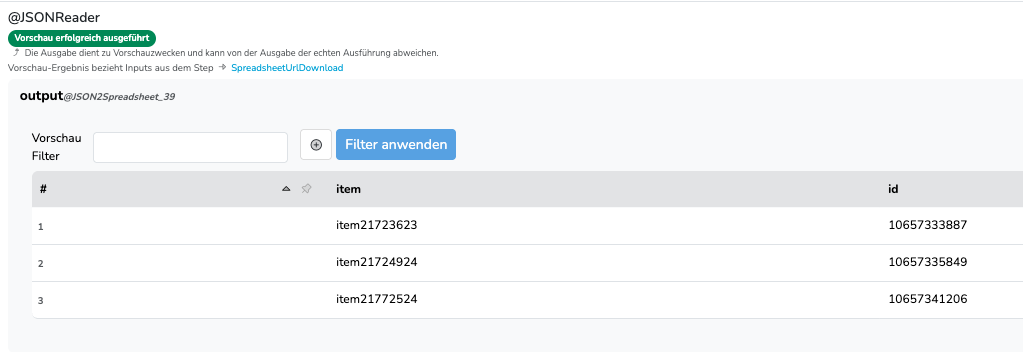
Als Reponse bekomme ich folgendes zurück:
{"data":{"item0":{"id":"10578450997"},"item1":{"id":"10578432599"},"item2":{"id":"10578444102"}},"extensions":{"request_id":"f308b7f3-f790-9329-a49b-a819a5e5bdce"}}
Ich möchte jetzt gerne die id, die zu jedem item (item0, item1, item2) zurückgekommen ist, in mein Datastore, dass als Identfier die “sku” hat, zurückschreiben.
Wenn ich den requestBody so umbaue, dass der Call nicht als Batch sondern als einzelner API Call versendet wird, bekomme ich mit Hilfe der Einstellung ‘outputSourceColumns’ die SKU sauber durchgeleift und kann diese dann per Datastore Writer weiterreichen. Nur beim Batch Versand weiß ich nicht so wirklich, wie ich das Ganze sauber zurückschreiben kann.
Hat jemand eine Idee?
Viele Grüße
Ramin