Hallo zusammen,
wie grade schon in der Runde angesprochen, hier mein Beispiel zu dem ColumnSplitToColumns.
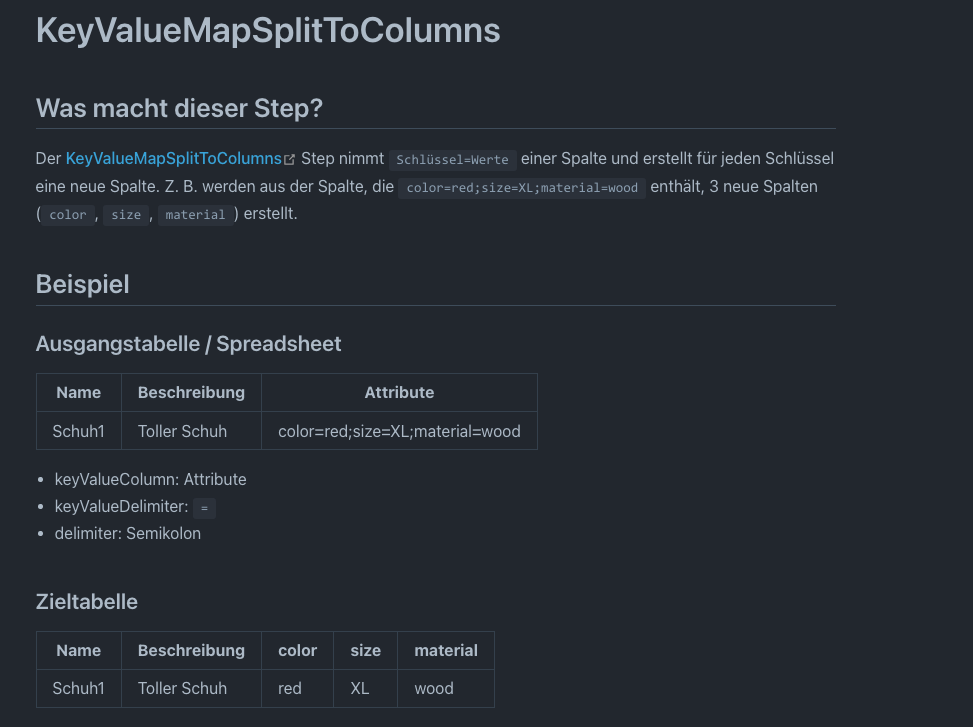
Es geht darum, aus einer Spalte mit Schlüssel-Wert-Paaren eine Spalte pro Schlüssel zu erstellen.
Meine Eingangsdaten sehen wie folgt aus:
| id |
key_value_col |
| 1 |
farbe=rot;größe=s;feature=bla |
| 2 |
farbe=blau;größe=s |
| 3 |
farbe=rot;größe=m |
| 4 |
farbe=blau;größe=m;preis=10 |
Und als Output wünsche ich mir folgendes:
| id |
farbe |
größe |
feature |
preis |
| 1 |
rot |
s |
bla |
|
| 2 |
blau |
s |
|
|
| 3 |
rot |
m |
|
|
| 4 |
blau |
m |
|
10 |
Beim Konfigurieren im Step würde ich spontan die folgenden Parameter erwarten:
- column: key_value_col
- key value seperator: =
- delimiter: ;
- Und möglicherweise noch ein optionalen Standardwert für nicht vorhandene Key-Value-Paare?
Die Funktionsweise ist vermutlich selbsterklärend, aber hier nochmal eine kurze Beschreibung.
Pro einzigartigen Schlüssel in meiner angegeben Spalte soll eine neue Spalte erstellt werden, die nach dem Schlüssel benannt ist.
Pro Zeile werden die Werte aus den Schlüssel-Wert-Paaren in die zugehörige neue Spalte eingetragen. Wenn ein Schlüssel in einer Zeile nicht vorhanden ist, bleibt die zugehörige neue Spalte einfach leer oder wird mit einem Default-Wert gefüllt.
Mit ein bisschen Freemarker-Magie kriegt man das über Umwege zwar schon hin, ein eigener Step dafür wäre aber deutlich angenehmer.
Gruß
Gustav
Vielen Dank für die detaillierte Beschreibung. Wir haben das als Ticket aufgenommen und machen uns Gedanken. Wir melden uns bei Rückfragen, oder wenn wir abschätzen können, wann wir es einplanen.
Wir haben das geprüft und wir werden einen Step dafür entwickeln.
Bleibt noch die Frage nach einem griffigen Namen.
Vorschläge:
- KeyValueColumnToColumns
- KeyValueMapToColumns
- ExpandKeyValueColumn
- ExpandKeyValueMap
- ColumnToColumns
- ExpandColumn
Das höre ich gerne.
Persönlich würde ich zu einem Namen mit „Split“ tendieren, weil unter dem Schlagwort auch die ganzen anderen Schritten benutzt, die irgendeinen Sache aufteilen. Ich persönlich sehe beides als aufteilen, egal ob es jetzt in Zeilen oder in Spalten aufgeteilt wird.
- KeyValueColumnSplitToColumns
- KeyValueMapSplitToColumns
- SplitKeyValueColumn
- SplitKeyValueMap
Die beiden letzten finde ich zu generisch.
Gruß
Gustav
1 „Gefällt mir“
Danke. Wir nehmen dann KeyValueMapSplitToColumns.
Wir haben dann nächste Woche etwas testbares.
1 „Gefällt mir“
Der Step KeyValueMapSplitToColumns ist jetzt live.
Doku entsteht noch.
Sehr cool. Ich werde später mal was basteln und berichte dann!
Hallo Team,
wäre es möglich, da noch ein Präfix-Feld einzufügen? Ich habe hier z.B. VariationSalesPrices à la „1=59.66;2=35.00;5=78.88“ usw. Nach diesem Step habe ich dann Überschriften 1,2,5. Mit einer Präfix-Möglichkeit „Preis_“ könnte das z.B. dann Preis_1, Preis_2, Preis_5 sein. Alternativ würde ich einen nachfolgenden ColumnRenamer darauf ansetzen, aber der müßte dann in der Lage sein, Regex zu verarbeiten, etwa so:
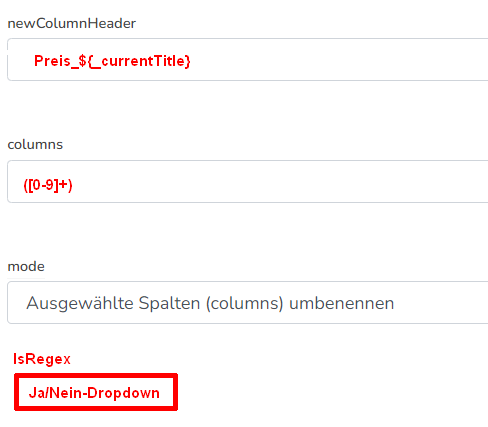
Im Moment sehe ich nur die Chance, die Ausgangsspalte per list-Anweisung selber auf das Format Preis_1=59.66;Preis_2=35.00 usw. zu bringen, bevor ich KeyValueMapSplitToColumns darauf ansetze - geht zwar auch, ist aber irgendwie umständlich. Meine favorisierte Lösung wäre übrigens, den ColumnRenamer Regex-fähig zu machen, weil ich schon öfters an der Stelle war, daß das nützlich gewesen wäre. Was meint ihr?
Gruß, Micha
podcomm e-commerce management
Hallo Micha,
du kannst dir auch über einen vorherigen HTMLWriter alle Spalten auflisten lassen, die deine Regex matchen. Hier im Beispiel werden alle Spalten aufgelistet, welche mit „Empty“ anfangen.
${spreadsheet@SpreadsheetCSVReader_5.getHeader().getCols()?filter(x -> x?matches("^Empty.*"))?join(",")}
Aber der Vorschlag den ColumnRenamer regexfähig zu machen, kriegt trotzdem ein +1, finde ich gut.
Gruß
Gustav