ich habe eine Frage zum Gruppieren in einem Mapper Step.
Hat jemand eine Idee, wie man das beschleunigen könnte?
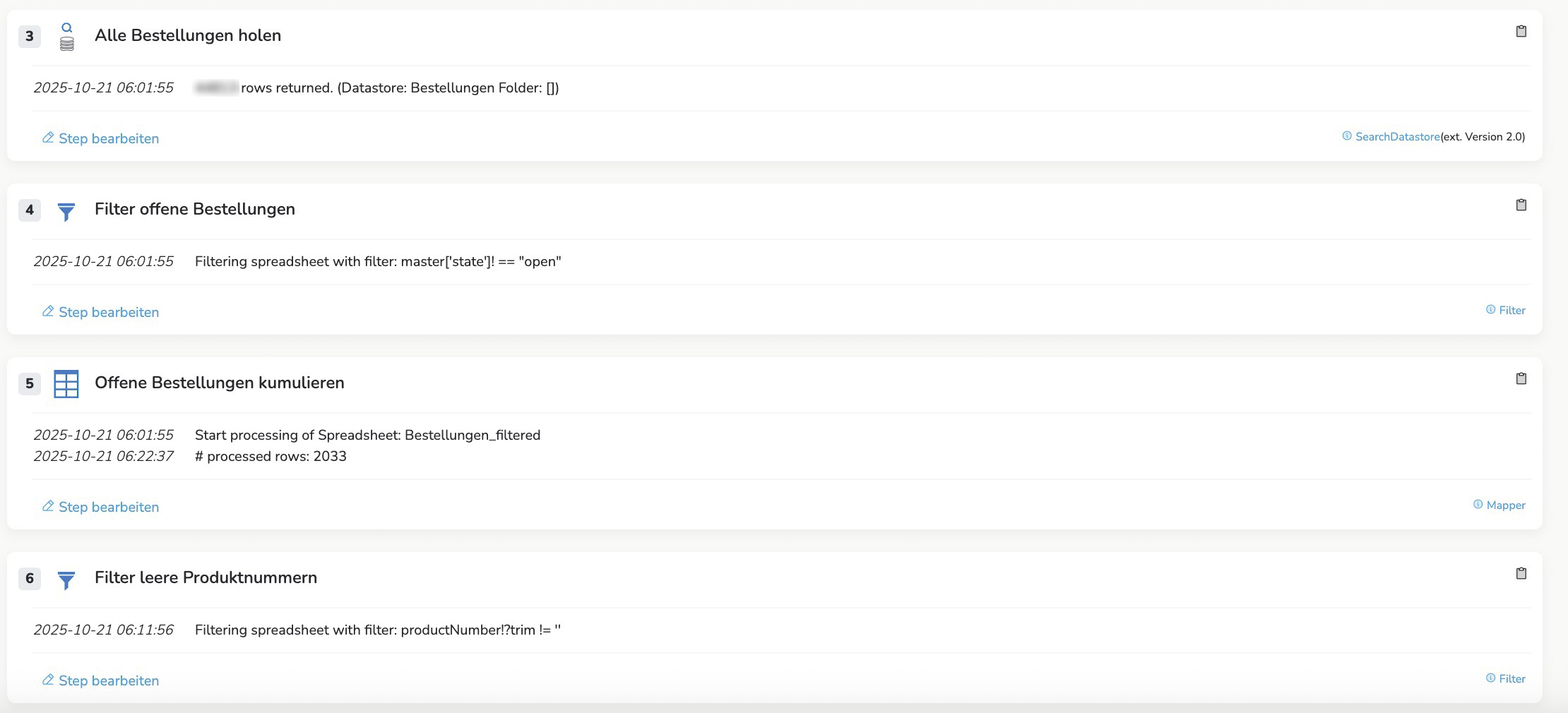
Es geht darum, dass wir aus einem Master Datastore alle Bestellungen mit den Bestellpositionen (Children) holen und nach dem Status des Masters “open” filtern (master[‚state‘]! == „open“). Da bleiben dann ca. 1500-2000 Bestellpositionen übrig, die dann in einem Mapper gruppiert und nach Bestellmenge summiert werden. Das dauert etwa 12 Minuten. Da wir das Ganze auch noch nach Status “In Bearbeitung” gruppieren/summieren dauert der ganze Flow ca. 24 Minuten (manchmal sogar über eine Stunde).
Wir haben auch versucht das Ganz mittels Freemarker Skript in einem TextHTMLWriter Step zu machen, was aber genauso lange dauert.
Hat jemand vielleicht eine Idee, wie man das beschleunigen könnte?
Caching hilft hier leider nicht, da die Daten nach dem Mapper direkt wieder in einen Datastore geschrieben werden und nicht weiterverarbeitet werden.
hast du mal getestet, wielange die einzelnen Schritte benötigen? Die Gruppierung für um die 2000 Zeilen sollte eigentlich nicht so lange dauern.
Ich vermute, die Zeit geht beim Filtern der Positionsdaten bzw. beim Abruf des Status vom Master verloren. Schätze mal, du hast eine ganze Menge an Positionszeilen vor dem Filtern auf „open“-Orders?
Um dort massenhafte Zugriffe auf den Master zu vermeiden, sehe ich zwei Optionen.
Du pflegst den Status des Bestellkopfs auch an den Positionen. So kannst du den Master-Zugriff komplett weglassen
Du drehst den Flow um und rufst die Kopfzeilen ab, filterst diese auf offene Bestellungen und rufst dann über die children die Daten von den Positionen ab. (Siehe hier für ein Beispiel von Synesty).
Wenn du den „Open“-Status auch in dem Processing-Status von Synesty abbilden kannst, kannst du auch in einem SearchDatastore-Step direkt die Master + Children abrufen, wo der Master den zu „open“ korrespondierenden Processing-Status hat.
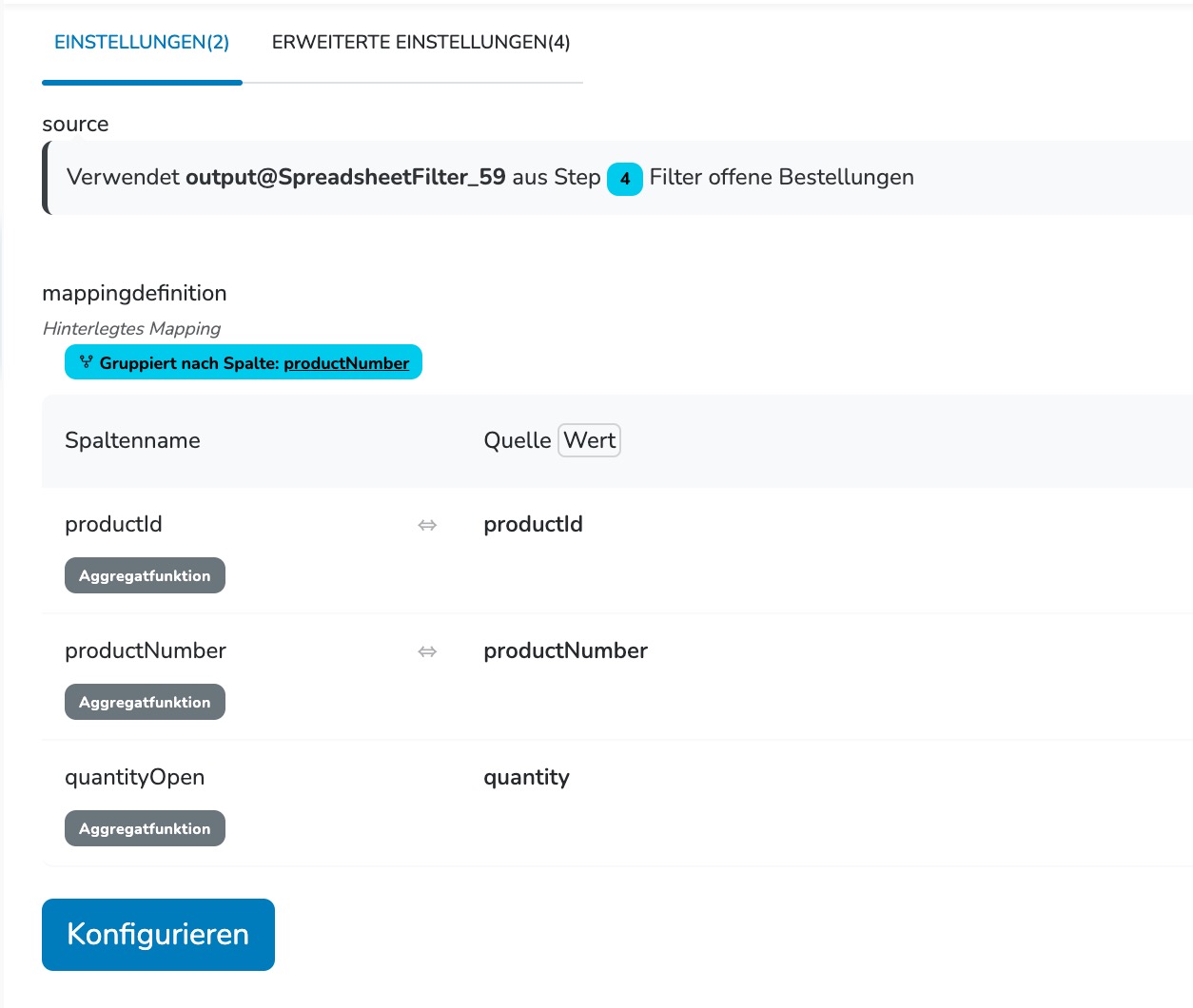
Mich wundert es eben auch, dass das so lange dauert. Es sind zwar schon relativ viele Spalten im Input, allerdings nur 3 Spalten mit Aggregatfunktion im Output.
die Stepausführungszeiten täuschen. Da die Verarbeitung im Endeffekt zeilenweise geschieht, lässt sich die Endzeit beim Filtern nicht feststellen. Am besten stellst du einmal testweise das Caching ein oder lässt dir den Output des Filters als Excel ausgeben. Dann siehst du, wielange der Filterschritt tatsächlich brauch.
Gustav hat schon viele, gute Hinweise gegeben. Trotzdem noch ein paar kleine Anmerkungen von mir dazu.
Die Zeiten im Eventlog sind manchmal aufgrund der „lazy“ Verarbeitung verwirrend.
Wenn ich es richtig sehe, wird Mapper(Step 5) 2x durchlaufen. Der 1. Durchlauf scheint nach knapp 10 Minuten fertig zu sein. Das kann man an der Startzeit des Filters (Step 6) erkennen.
Es sollte sich eigentlich schon „lohnen“ den CacheMode im Mapper(Step 5) zu aktivieren.
Ein paar zusätzliche Informationen dazu findest du unter.
Ich vermute aber auch, dass der größte Teile der Laufzeit bei der Filterung (Step 2) verbraucht wird.
Für alle (Child)-Ergebniszeilen der SearchDatastore Steps wird im Filter zusätzlich nochmal der Master Datensatz aus der Datenbank geholt (pro Zeile). Je nachdem wieviele Zeilen das sind kann das schon einige Minuten dauern.
Am meisten Zeit wirst du einsparen, wenn du die Anzahl der Zeilen im Ergebnis des SearchDatastore Steps reduzierst. Wie Gustav schon geschrieben hat, könntest du am Bestellkopf den status im Processing-Status oder im identifier2/3 oder „open“ als Tag am Datensatz setzen. Damit kannst du dann im SearchDatastore Step filtern und die Anzahl der Ergebnis-Zeilen reduzieren.
Ich habe jetzt mal ein paar Tests gemacht.
Das einstellen des Caches hat keine Verbesserung gebraucht, das beeinflusst die Laufzeit nicht.
Ich habe auch mal einen Lauf gemacht, bei dem ich die Mapper-Steps mit dem Gruppieren deaktiviert habe. Dadurch hat sich die Ausführungszeit auf wenige Sekunden reduziert.
Den Processed-Status wollte ich aktuell mal nicht anfassen, da ich dadurch in einigen anderen Flows diverse Anpassungen machen müsste, sowie an den bestehenden Datensätze.
Ich überlege mal weiter, ob es vielleicht noch einen anderen Workaround gibt.
Danke euch nochmal.
Viele Grüße,
Patrick
EDIT:
Wir haben den Step, der die Daten aus dem Datastore holt, mal mit einem Datum eingeschränkt, so dass nur noch etwa die Hälfte Bestellungen geholt werden. Das hat die Gesamtlaufzeit des Runs schon mal von ca. 24 min auf 13 min reduziert.
Vielleicht da noch ein Frage dazu @synesty-Torsten : Man könnte ja auch theoretisch den Bestellstatus in den identifier3 schreiben und dadurch im SearchDatastore Step filtern. Weiß aber nicht, ob das eine gute Idee ist?!
Wenn du den identifier3 in den anderen Flows nicht benötigst, kannst du diesen auch für die Filterung im SearchDatastore verwenden.
Nachteil ist natürlich, dass dieser dann mit dem Bestellstatus belegt ist. Falls du den identifier3 irgendwann für etwas anderes benötigst, müsstest du wieder umbauen.
Ich habe jetzt mal für alle Bestellungen einen open/closed Status im identifier3 gesetzt und dann danach im SearchDatastore Step gefiltert. Das hat das Ganze wirklich immens beschleunigt. Der gesamt Flow benötigt jetzt nur noch ca. 50 Sekunden.