Hallo zusammen,
bin seit letzer Woche ein neuer Kunde und bin noch in der Findungsphase 
Ich habe gerade ein Projekt erstellt in dem ich eine CSV.Datei (URL) gerne einlesen lassen möchte und die entsprechenden Warenbestände sollen direkt zu Plenty API aktualisiert werden.
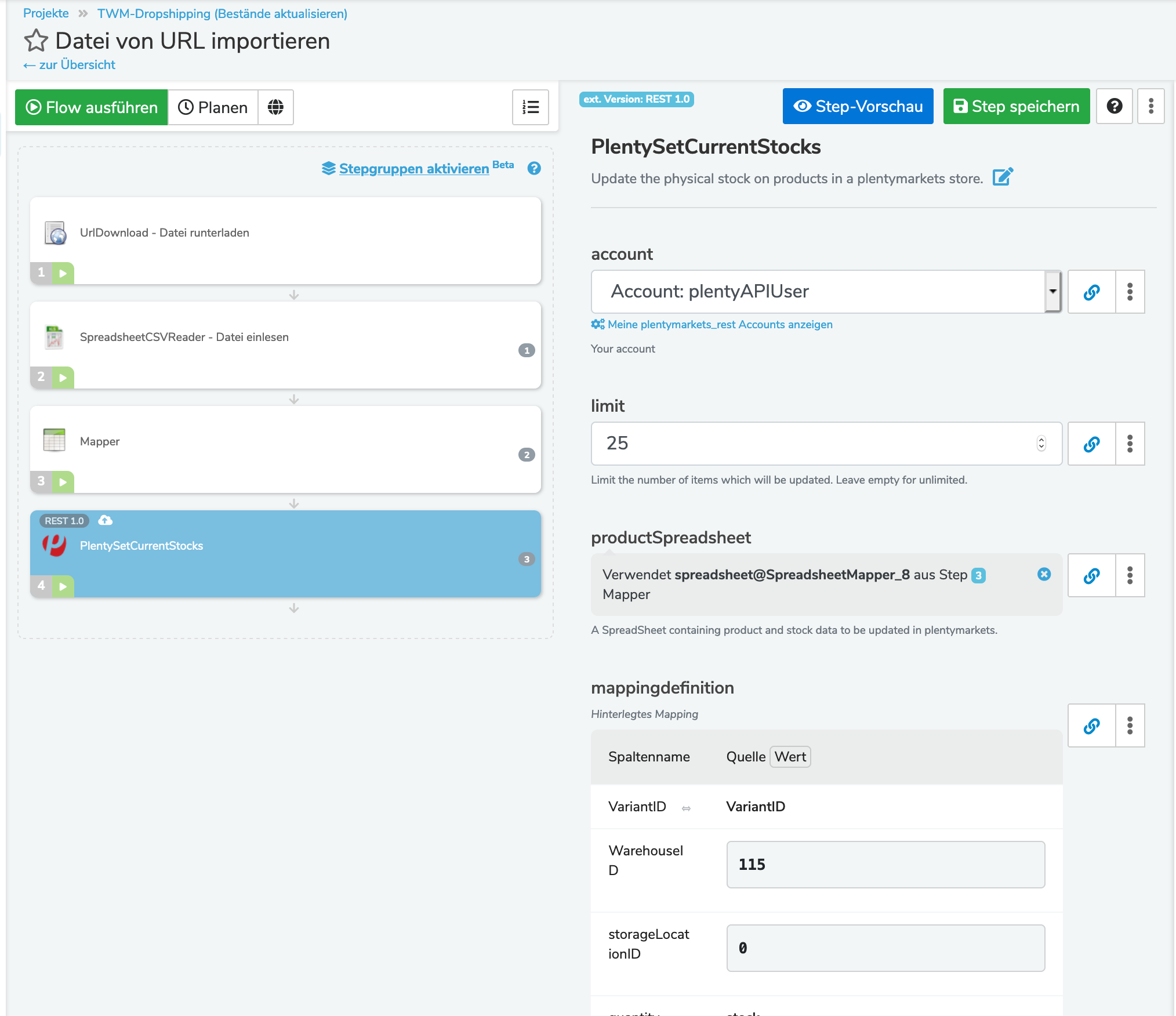
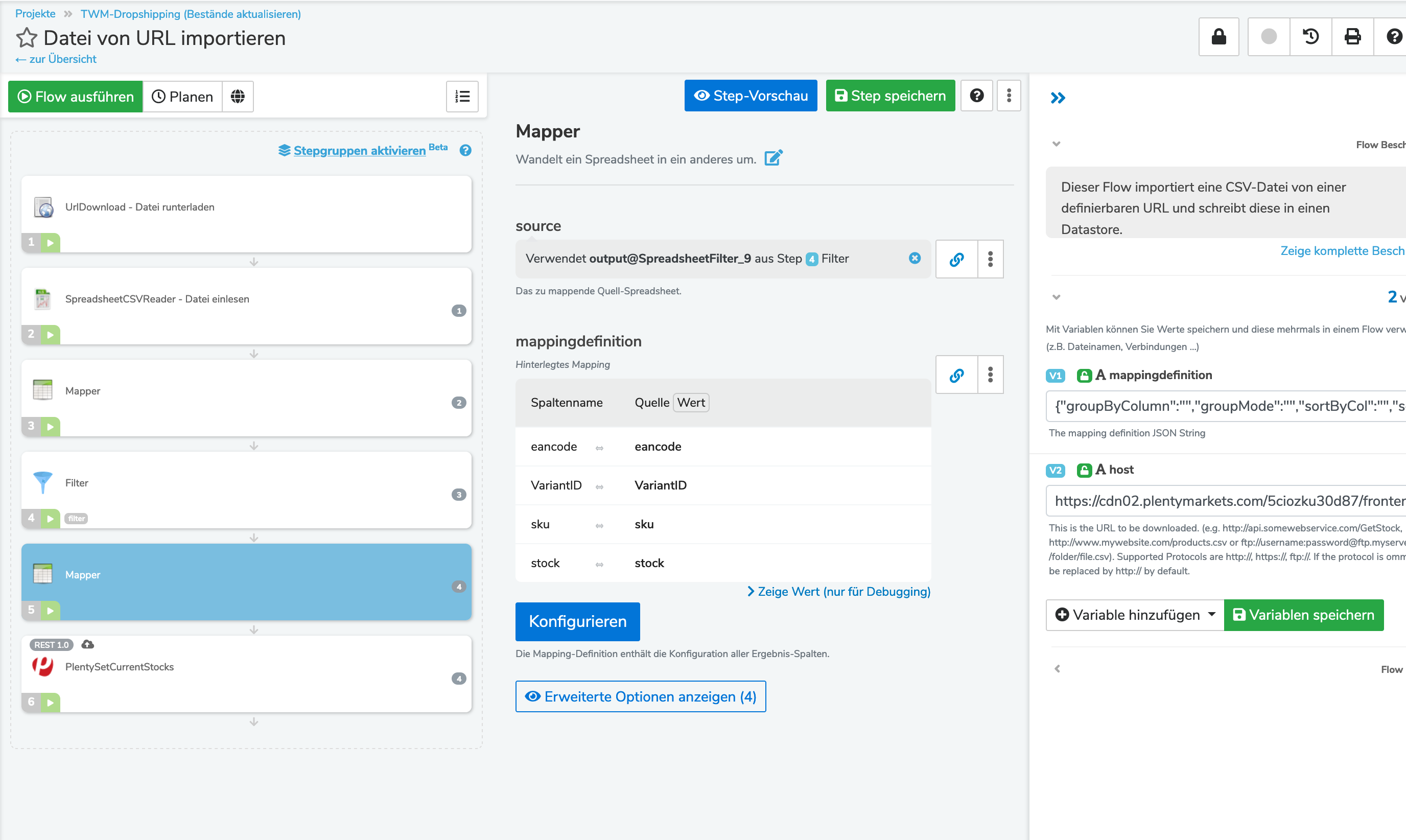
Nun wird mir im PlentySetCurrentStocks Step als Abgleichfeld die Varianten-ID angezeigt.
Ich möchte aber als Abgleichfeld gerne das EAN-Feld aus der CSV.Datei (URL) hinterlegen.
Wie tätige ich die Einstellung im entsprechenden Step?
Über eine Antwort würde ich mich sehr freuen.
Viele Grüße
Sascha
Leider kann man hier EAN nicht direkt setzen, weil die API von plenty das nicht hergibt.
Die Vorgehensweise ist hier meistens immer so, dass man sich erstmal alle Artikel von plenty abruft und in einem Datastore speichert. Wichtig ist, dass man in identifier die variantID speichert und sich z.B. in identifier2 die EAN speichert. Damit hat man die Voraussetzung um später dann per Querverweis über die EAN an die variantID zu kommen.
Ein Startpunkt wäre z.B. hier Datastore Import und Export - Synesty Studio Documentation - Synesty Documentation und Support
Hallo liebes Synesty-Team,
vielen Dank für die schnelle Hilfe.
Werde diesen Weg mal testen.
Gruß
Sascha
Hallo,
ich habe nochmal eine kurze Frage.
Habe den Querverweis Dank der guten Beschreibung mit dem Abgleich des Datastores hinbekommen.
Bevor ich den Flow starte, nun meine Überlegung.
Die Datei (Step1), welche per URL eingelesen wird, umfasst knapp 300.000 Zeilen mit den entsprechenden Beständen. In meinem Plentyshop befinden sich aber nur 300 Produkte davon, welche ich nun matchen lassen möchte, damit die entsprechenden Bestände aktualisiert werden.
Hat das irgendwelche Auswirkungen auf mein Limit oder wie gehe ich hier am besten vor?
Vielen Dank im Voraus für die Hilfe.
Gruß
Sascha
Super, und eine sehr gute Frage.
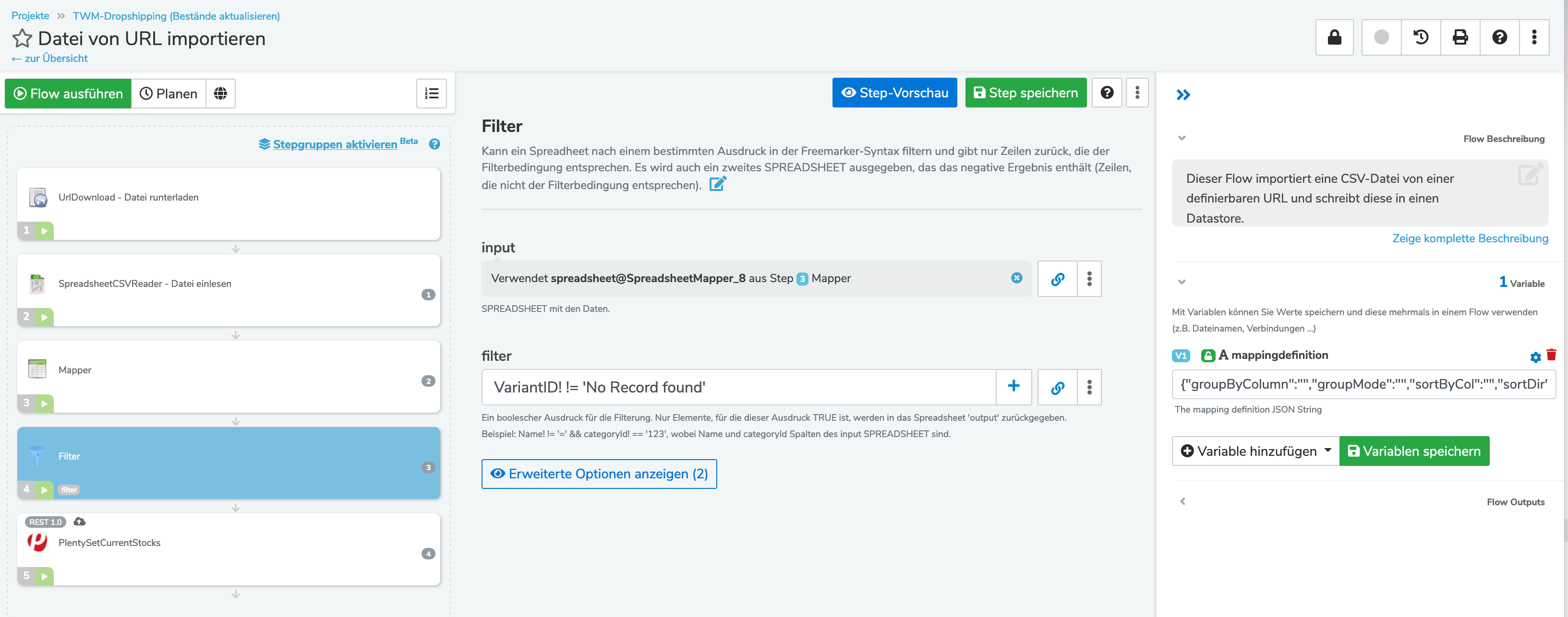
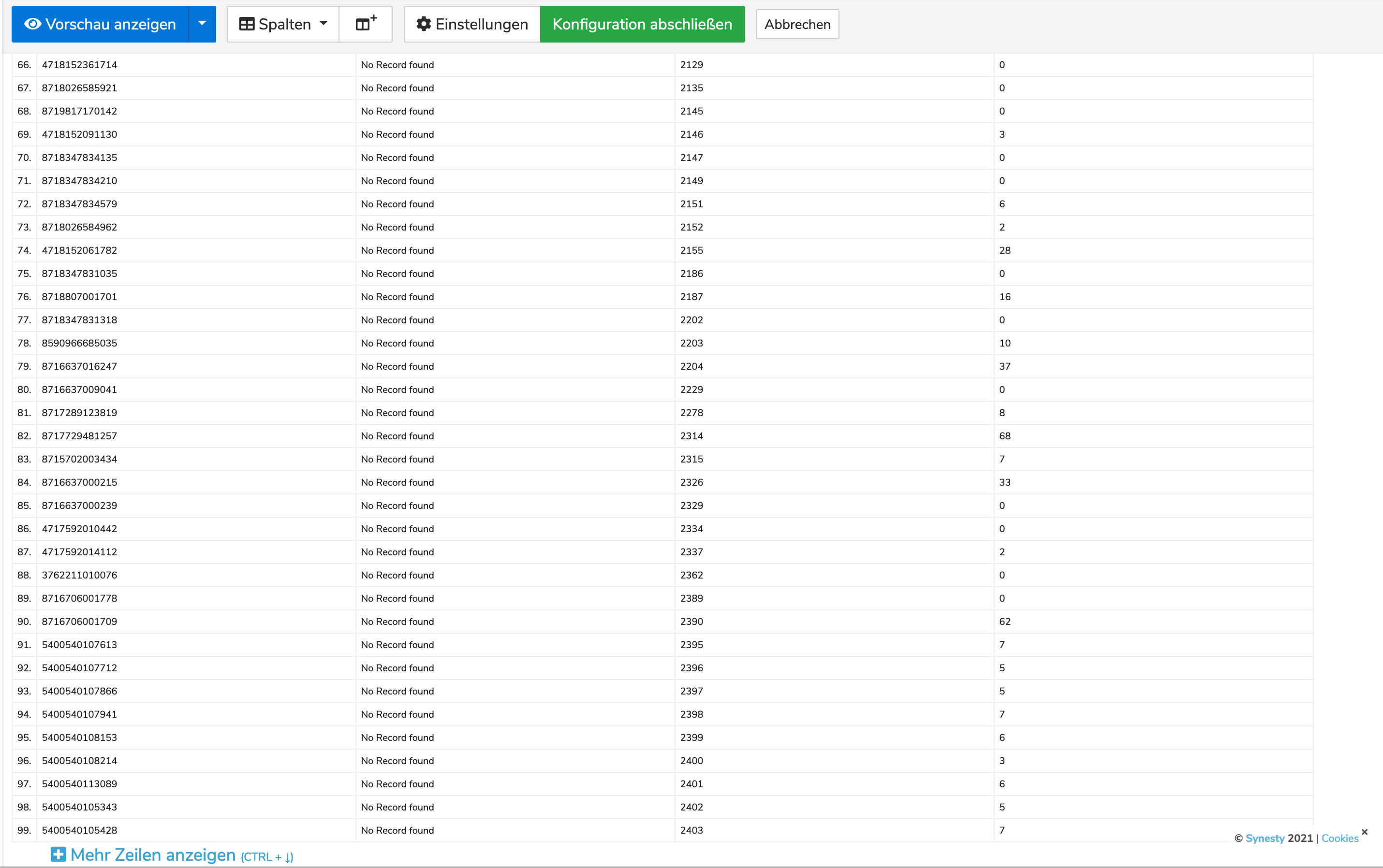
Sie sollten noch einen Filter nach dem Mapper einbauen, um alle Zeilen zu entfernen, die sie nicht im Plenty haben. Sie können diese Zeilen erkennen, wo der Querverweis im Mapper „No Record found“ ausgibt.
Das beschleunigt den PlentySetCurrentStocks step ungemein, da ansonsten tausende Fehler kommen würden.
Hier wird beschrieben wie sie mit dem Filter Step solche „No Record found“ Zeilen entfernen:
Wichtig: sie müssen dann das Ergebnis des Filters in den PlentySetCurrentStocks reingeben.
So langsam verstehe ich immer mehr
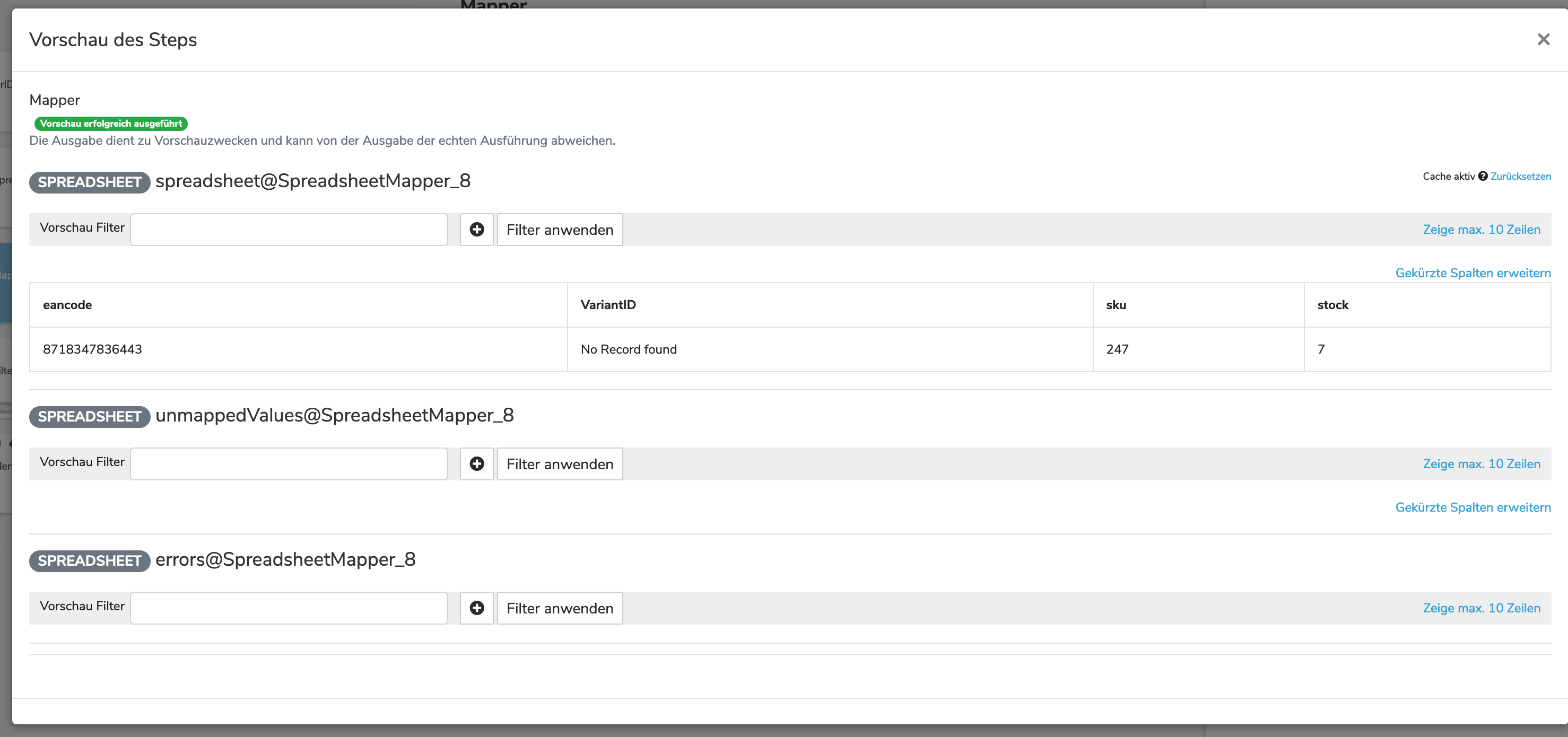
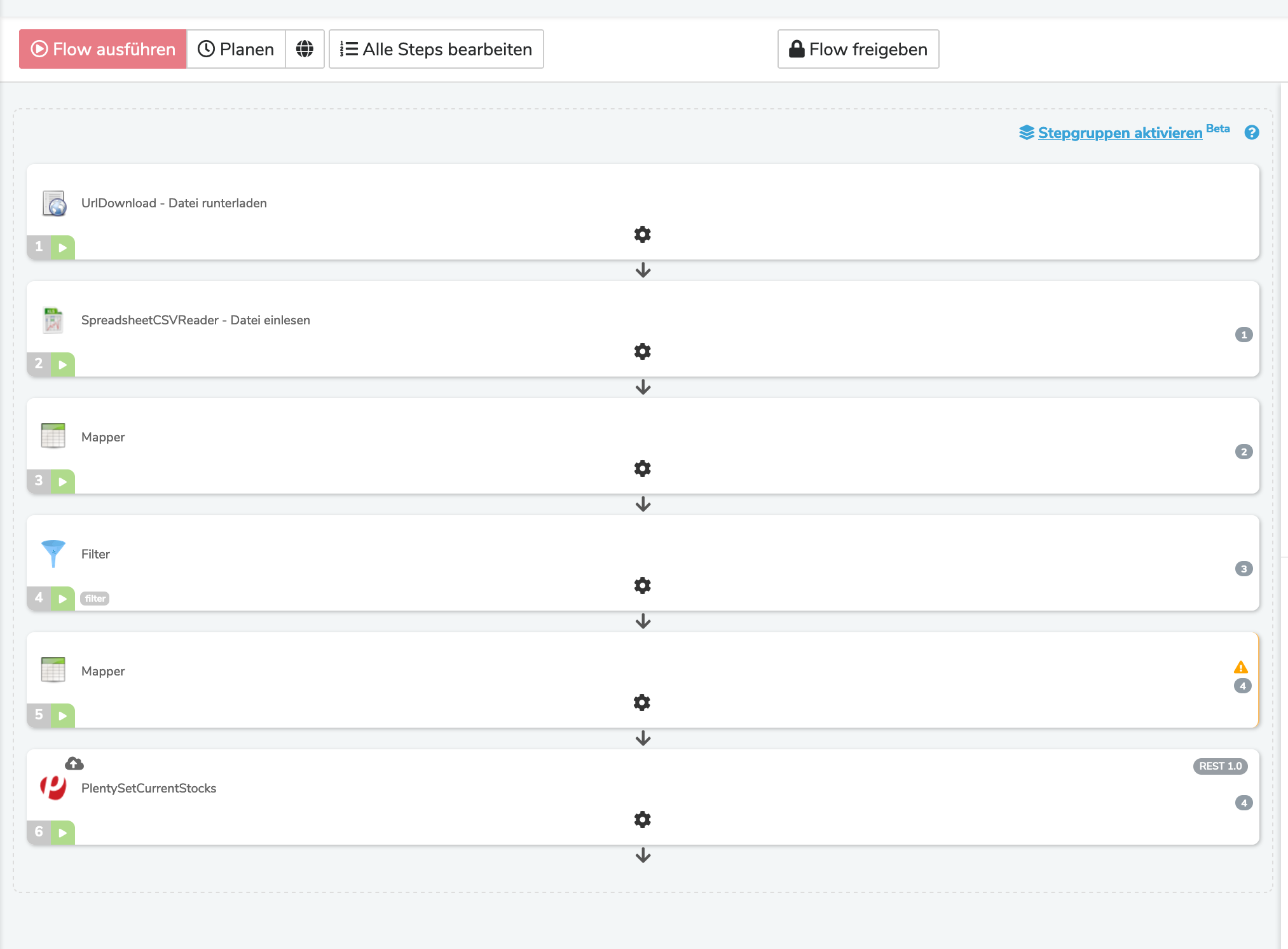
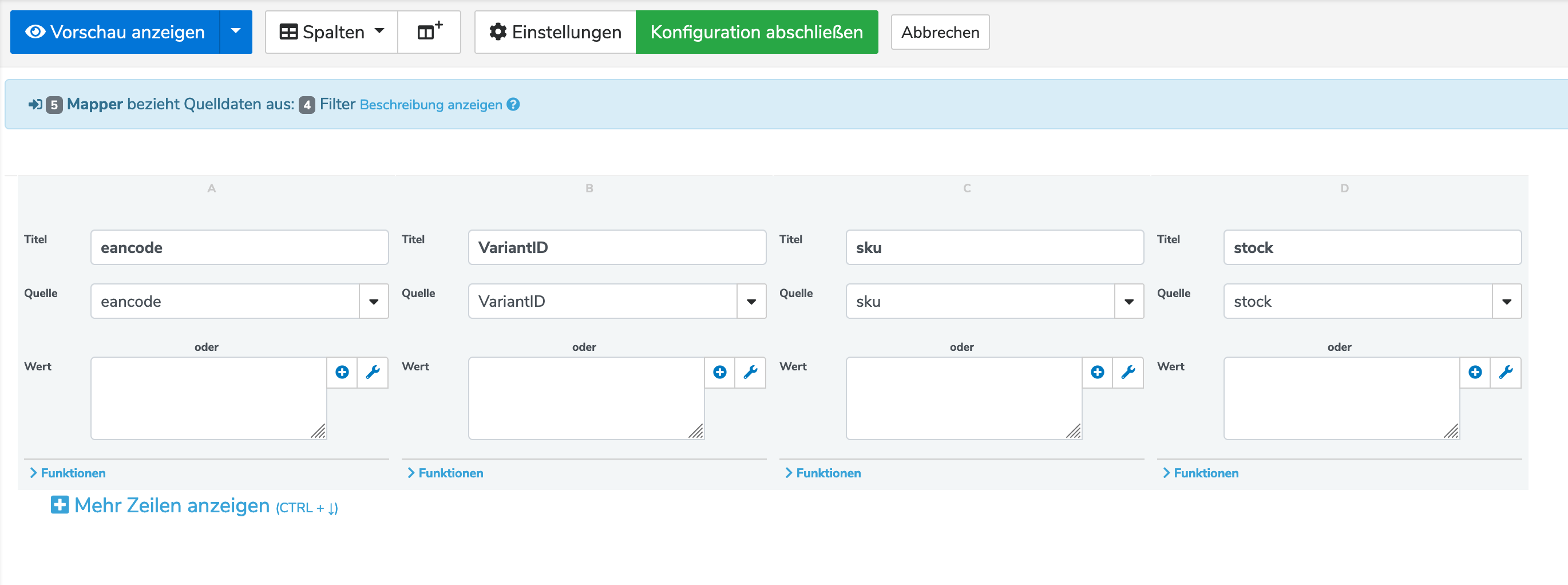
Habe nun den Filter gebaut und gesagt, dass alle Einträge in der Spalte „VariantenID“ wo der Querverweis drauf liegt, mit „No Record found“ entfernt werden sollen.
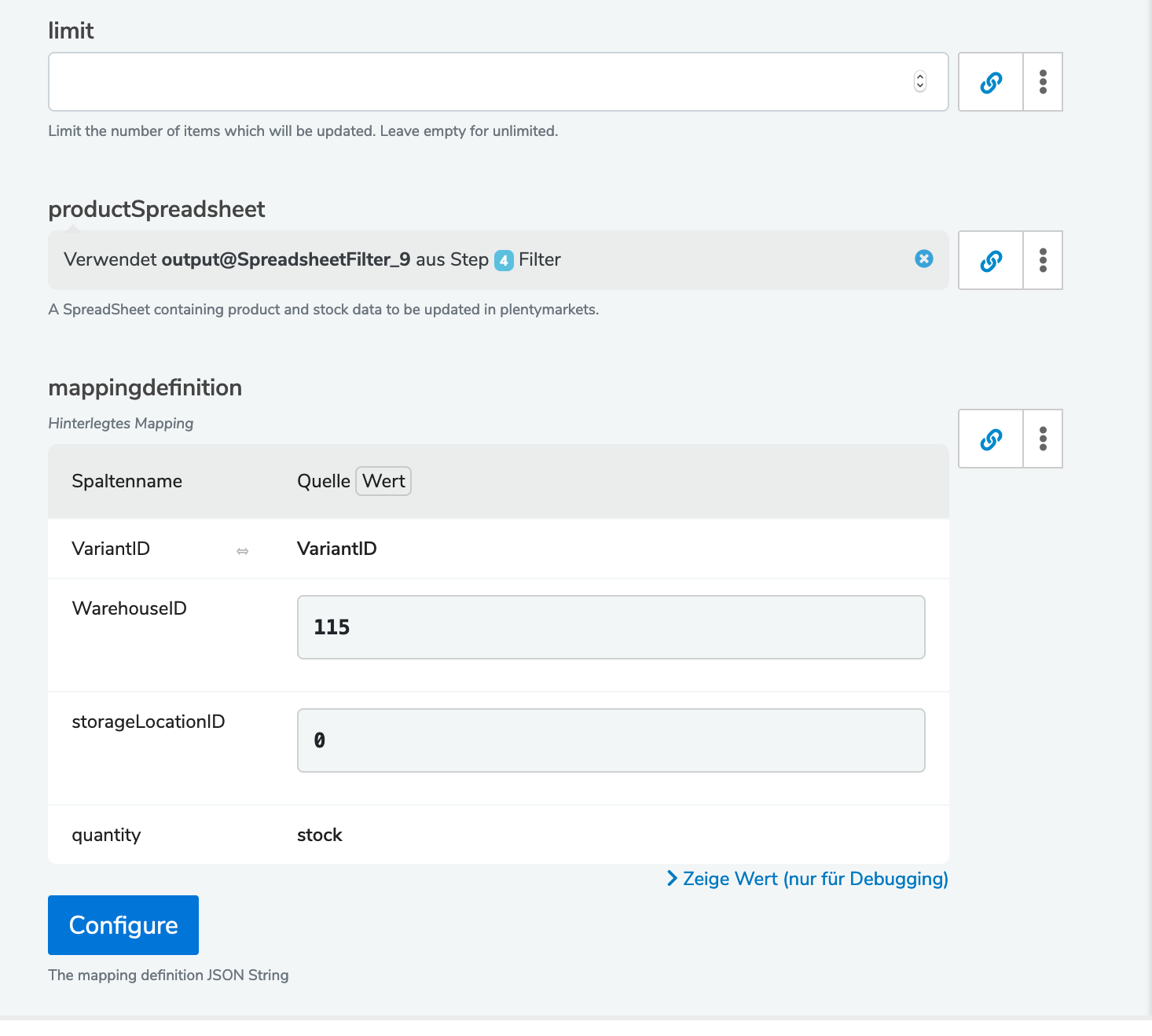
Dann habe ich den Filter im Step „PlentySetCurrentStocks“ hinterlegt:
Doch wenn ich mir nun die Vorschau anschaue, sehe ich nur Leerzeilen und keine Einträge.
Sollten denn jetzt nicht alle Zeilen aus der URL angezeigt werden, die mit dem Querverweis auf die VariantenID zu finden sind?
Anscheinend fehlt nur noch ein kleines Puzzelstück.
Erneut Danke für die Hilfe.
Gruß
Sascha
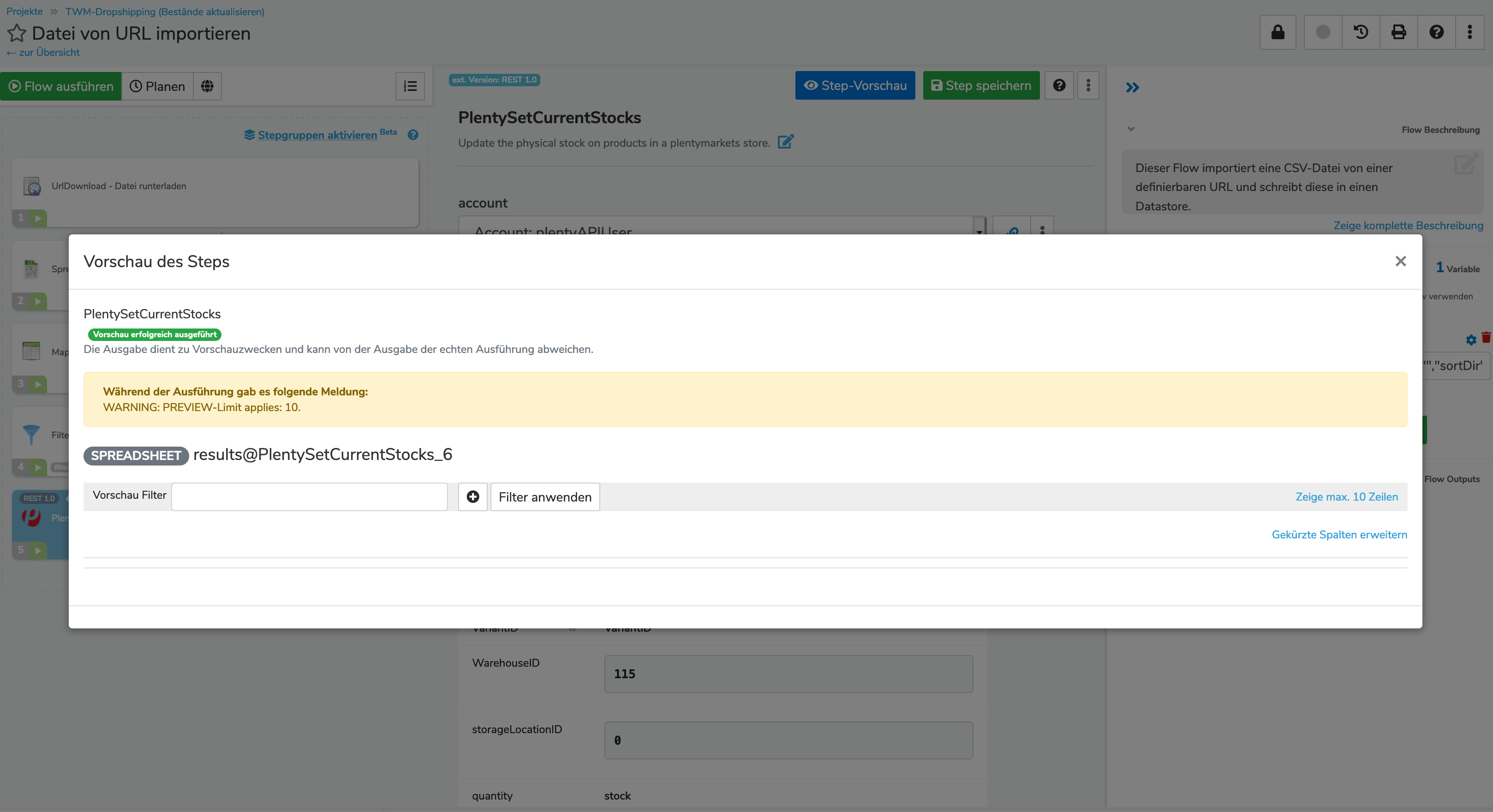
Kannst du mal einen Screenshot von der Step-Vorschau des Filters schicken? Kommt da auch etwas durch? Ansonsten gern auch mal noch eine Step-Vorschau des Mappers (sensitive Daten gern schwärzen)
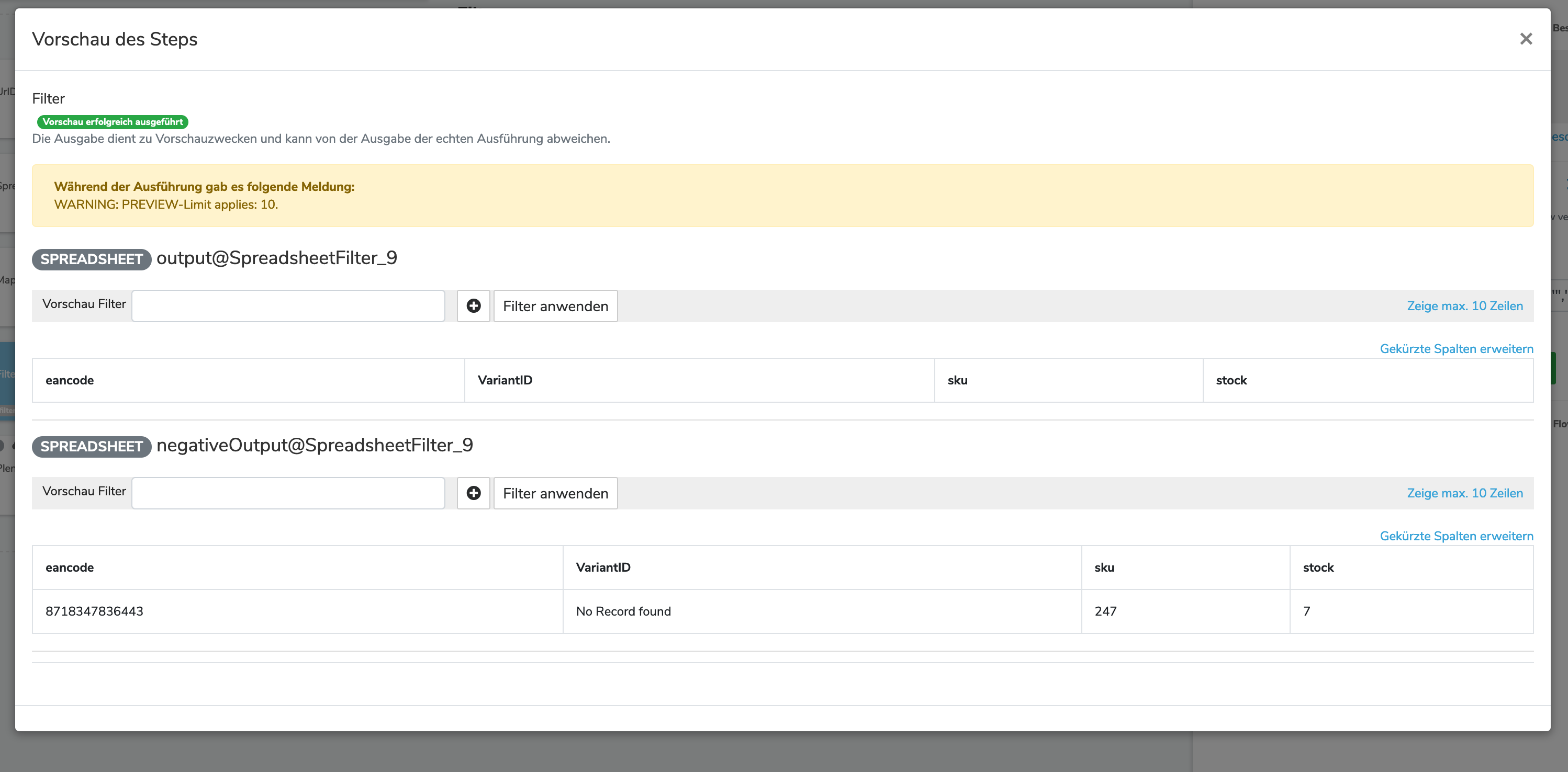
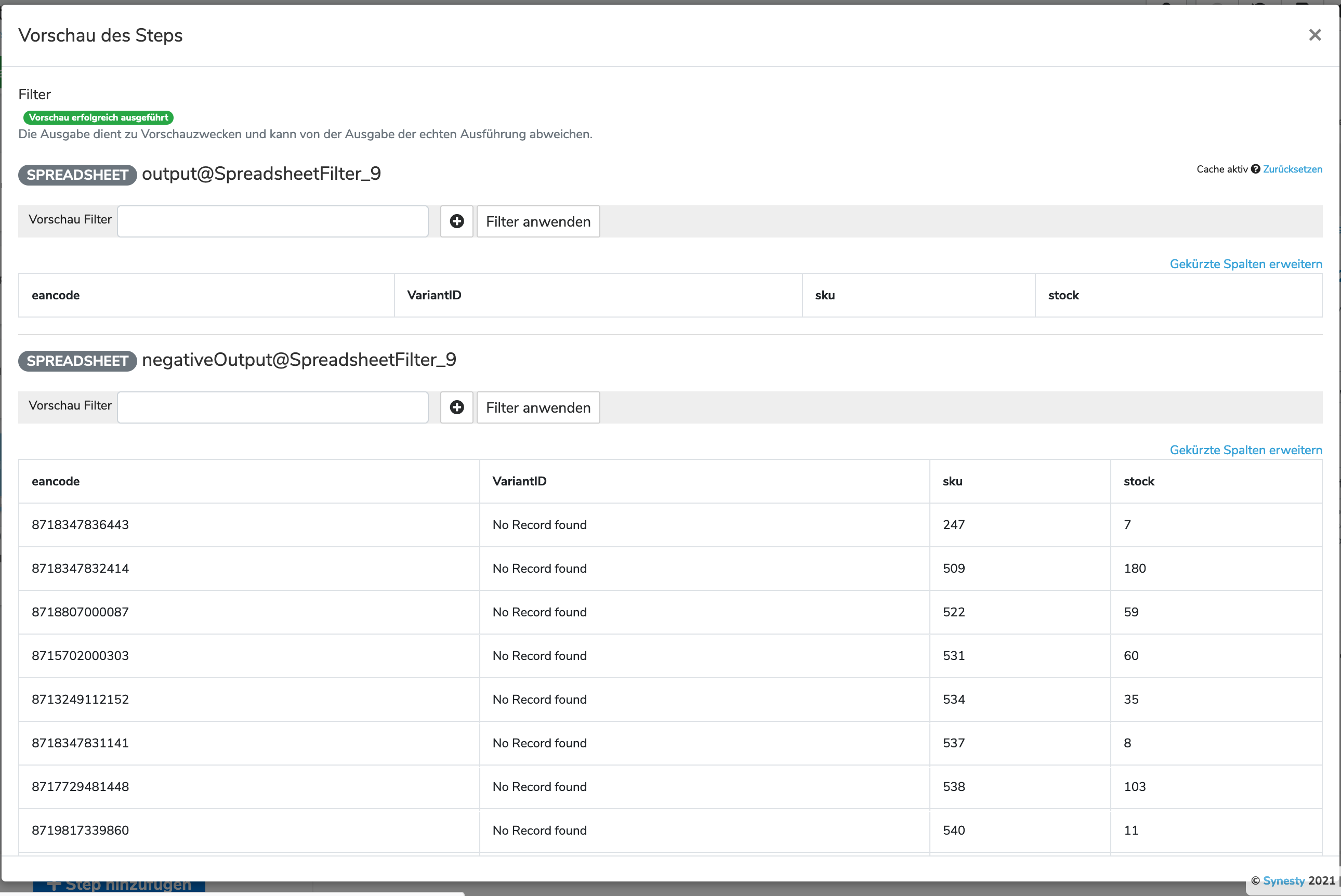
Anbei die beiden Screenshots vom Mapper und Filter:
Hmm also durch den Filter kommt nichts durch. Evtl. ist der Querverweis noch nicht korrekt?
Kannst du dir ggf. per Filter mal auf einen eancode ausgeben lassen, bei dem du sicher bist, dass es dazu eine VariantID gibt? Falls du dort eine siehst, aber der Filter nichts durchlässt, dann sind vielleicht irgendwie noch Leerzeichen dran. Der Filterausdruck !VariantID!?contains("No Record found") (?contains) könnte solche Leerzeichen ignorieren.
Mit anderen Worten: Erst wenn du mit deinen eigenen Augen eine korrekt gefüllte VariantID gesehen hast (wo nicht „No Record found“ drin steht), solltest du weiter machen.
Tip: Beim Testen möglichst mit kleineren Testdateien arbeiten. Du könntest dir z.B. mit einem Texteditor die Datei klein machen oder direkt hinter der CSV-Reader schon einen Filter packen, in dem durch dir eine ganz bestimmte Test-EAN filterst. Setze am besten auch immer ein niedriges Limit an den Steps beim Testen. Weil du möchtest nicht 300+ Artikel mit falschen Daten überbügeln.
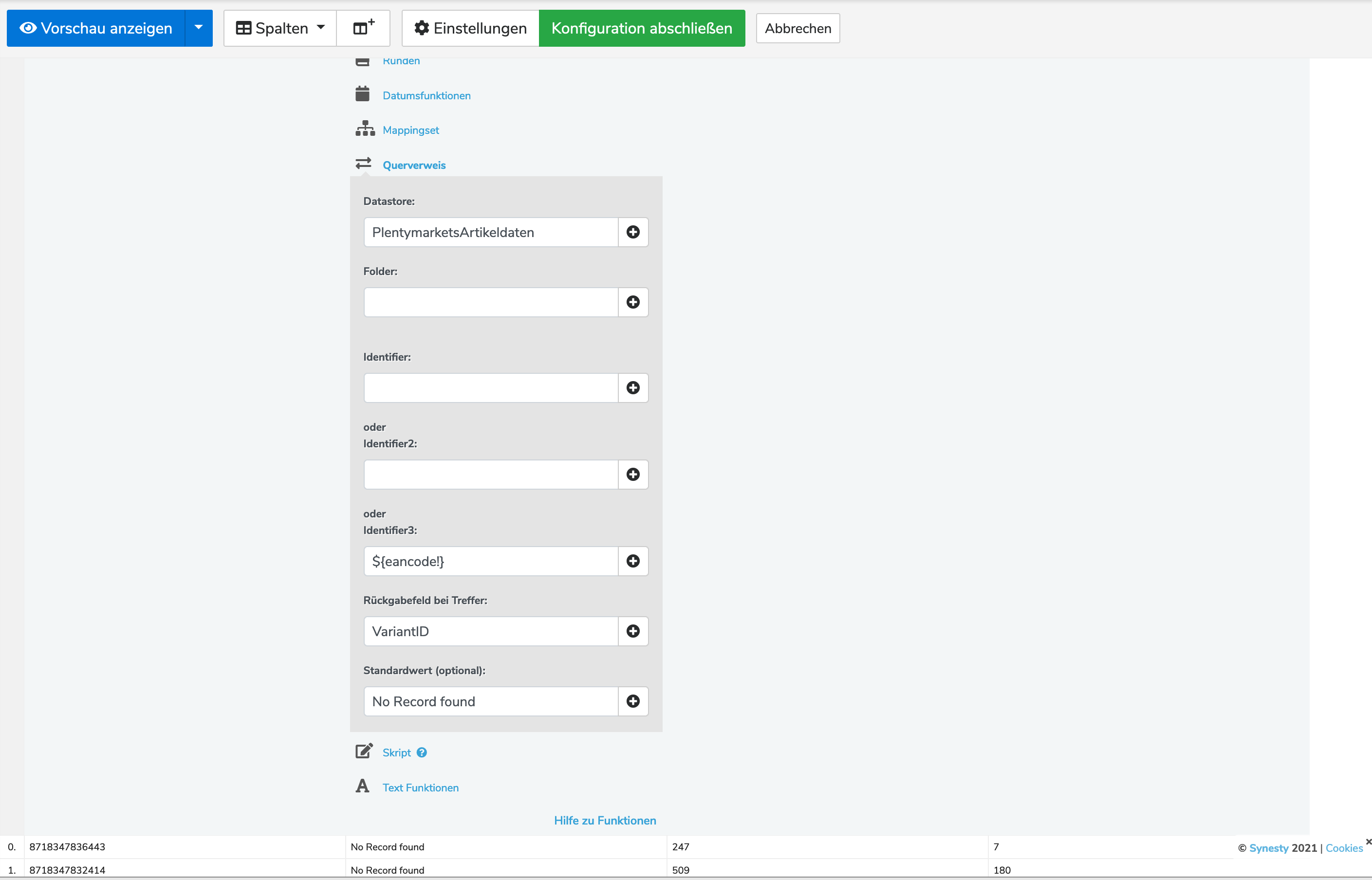
Puh, habe es endlich gefunden. Im Datastore wird das Feld „VariationBarcodes“ für den „identifier3“ rausgeworfen.
Das Feld „VariationBarcodes“ hat vor der EAN ein „1=“ und deswegen passt der Querverweis nicht.
Gibt es den in der API von plenty nicht das Barcode-Feld ohne den „1=“ ? Also nur die EAN abzurufen?
Viele Grüße
Sascha
Hallo Sascha,
versuch mal noch in dem Datastorewriter im Wert-Feld des Identifier3 folgendes einzutragen:
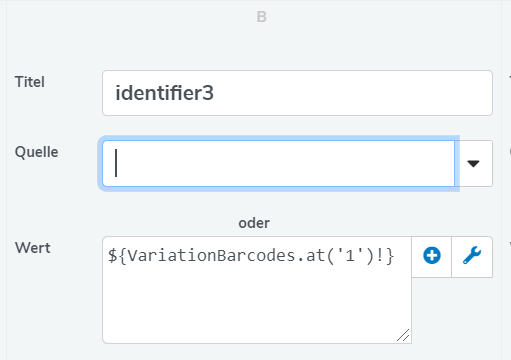
Denn die Barcodes aus Plenty werden als Key-Value Paar ausgeben. Das heißt mit der Angabe des Keys [1] greifst auf den Value [Deine EAN] zu.
Viele Grüße,
Lukas
1 „Gefällt mir“
Hallo Lukas,
super! Du konntest mir super weiterhelfen.
LG
Sascha
Hallo Lukas,
jetzt muss ich trotzdem nochmal nerven, da es einfach nicht klappt.
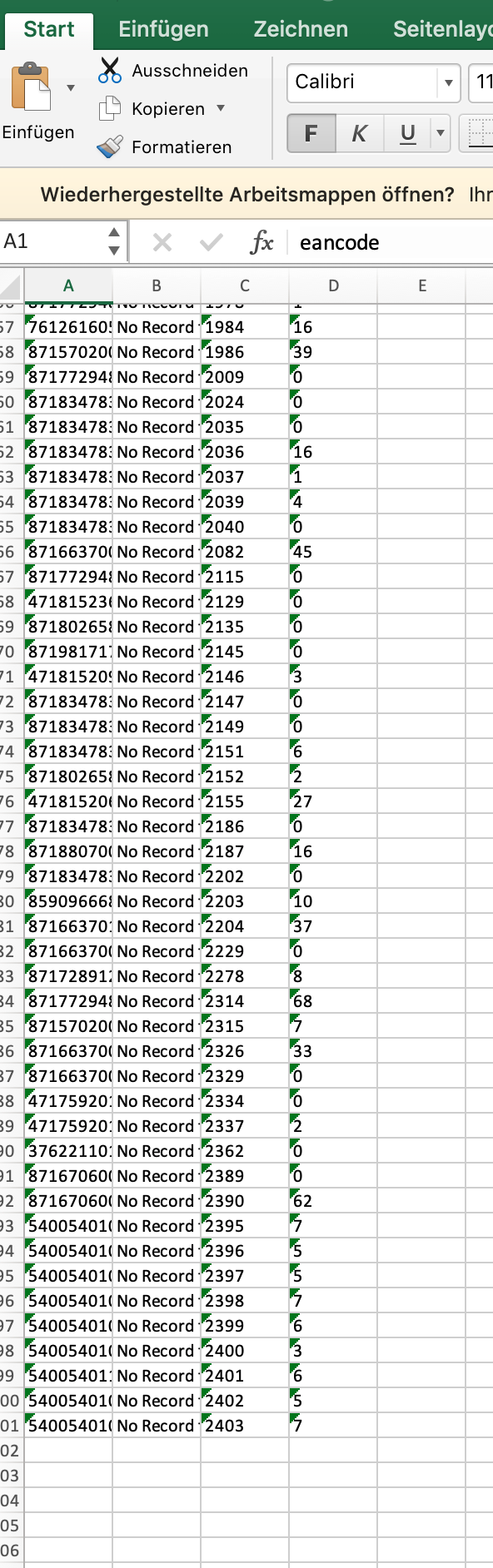
Es wird eine CSV. Datei als URL mit den Beständen abgerufen. Anbei mal der Download der Datei auch im Step zu finden ist.
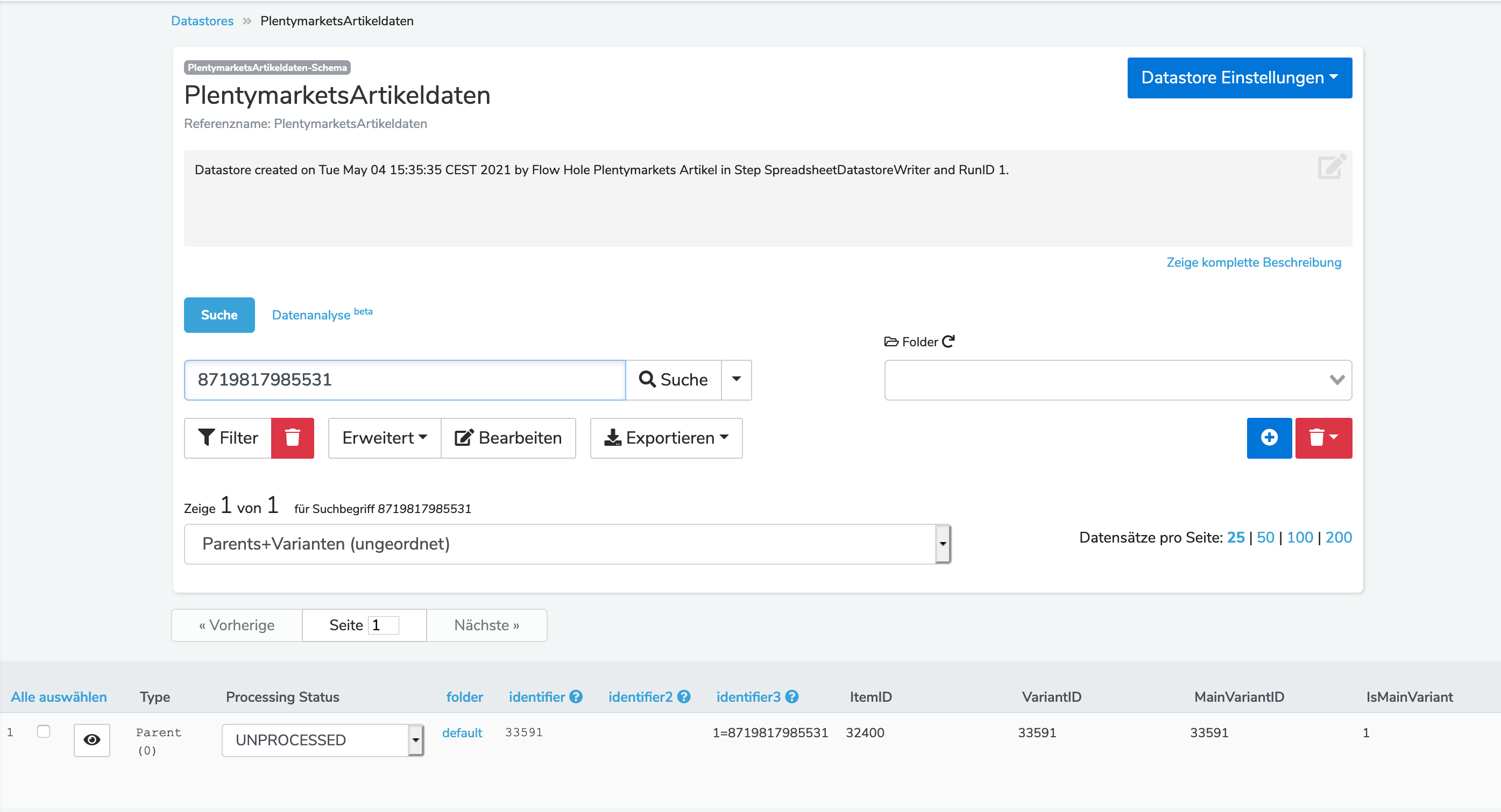
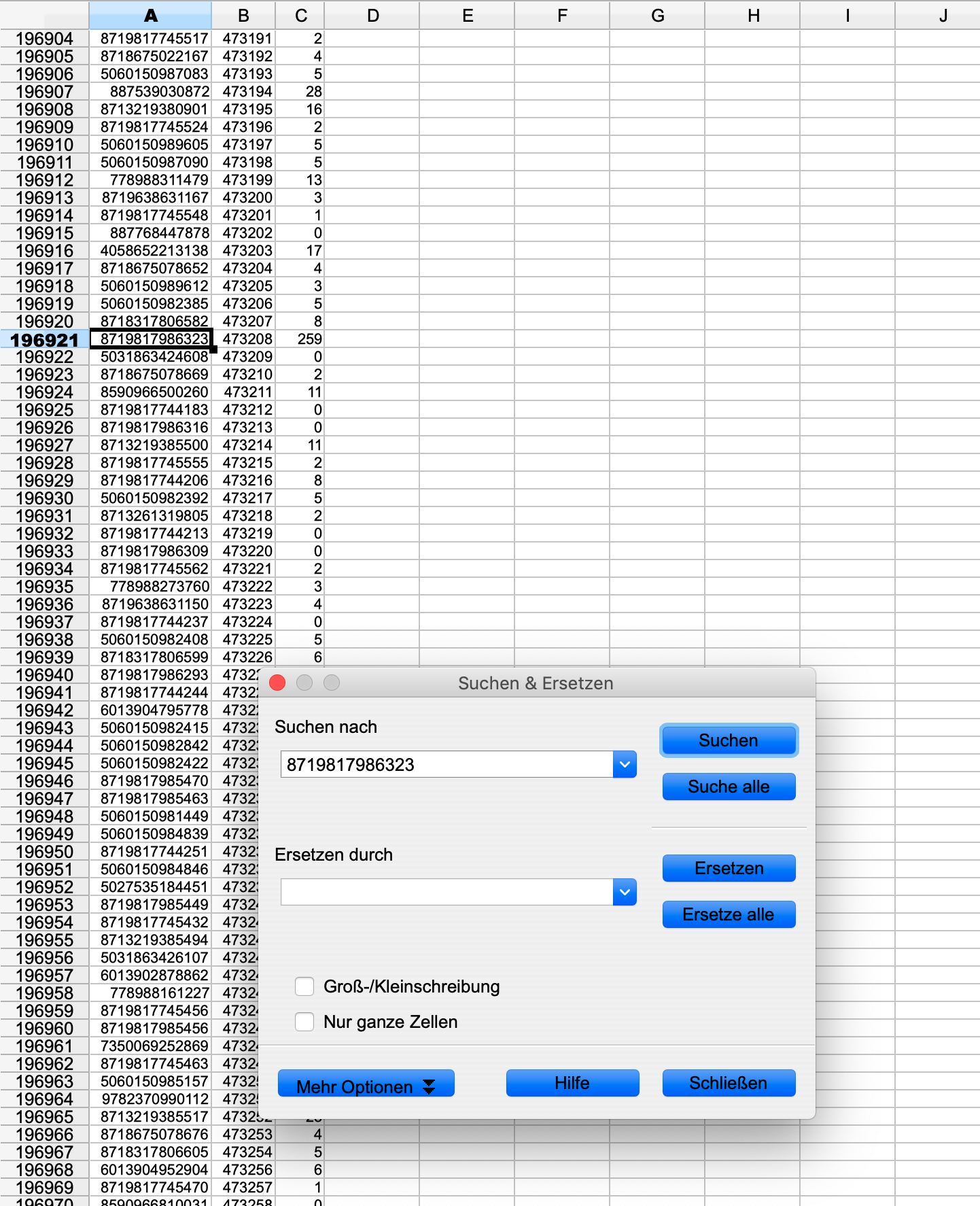
Ich habe mir nun mal eine Beispiel-EAN „8719817986323“ genommen und in der Datei gesucht und mit dem Datastore manuell abgeglichen:
Hier die EAN aus der CSV-Datei:
Hier die EAN aus dem DataStore:
Trotzdem wird nach dem Filter diese EAN nicht als positiver Input ausgegeben.
Verstehe alle Anforderungen total.
Wir wollen eigentlich auch noch weitere ADDon´s buchen und Synesty nutzen, jedoch scheitern wir schon bei so einem einfachen Thema.
Habt Ihr noch eine Idee?
LG
Sascha
Hallo Sascha,
dein Vorgehen und der Aufbau sieht soweit korrekt aus. Kannst du bitte mal eine Sache testen und nach dem Filter noch einen Mapper hinzufügen, der mit dem Filter verknüpft ist. Anschließend in den Mapper gehen und auf den Button „Daten aus vorherigen Steps holen“.
Wird da dann immer noch kein Ergebnis angezeigt?
Viele Grüße,
Lukas
Hallo Lukas,
habe jetzt einen weiteren Mapper nach dem Filter hinzugefügt:
!
!
Es werden keine Zeilen angezeigt:
!
Weitere Ideen?
LG
Sascha
Hallo Sascha,
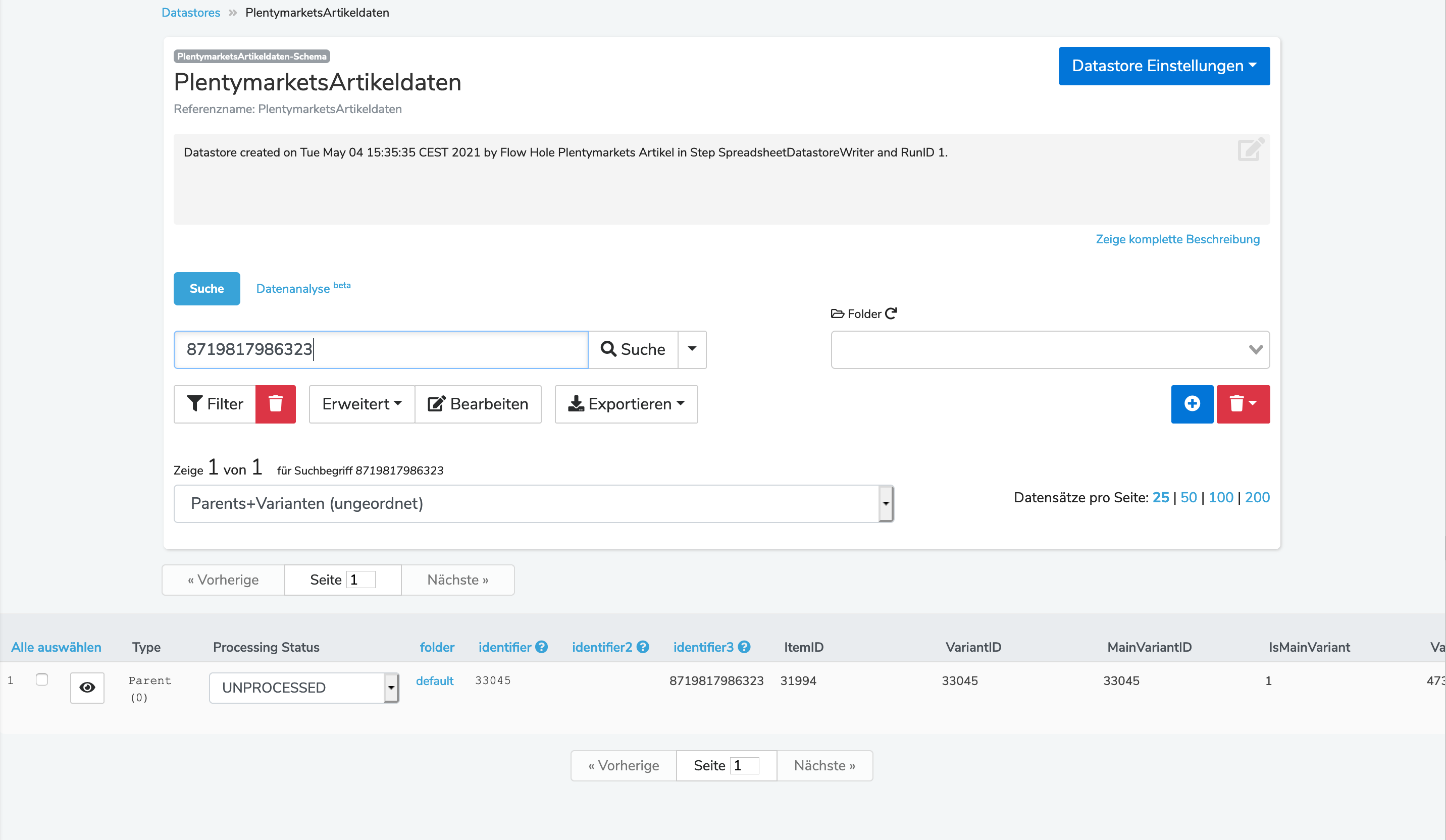
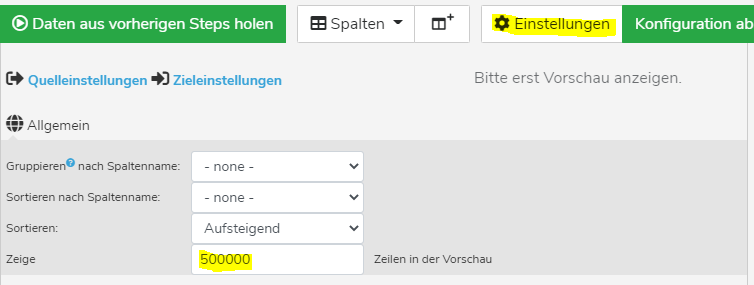
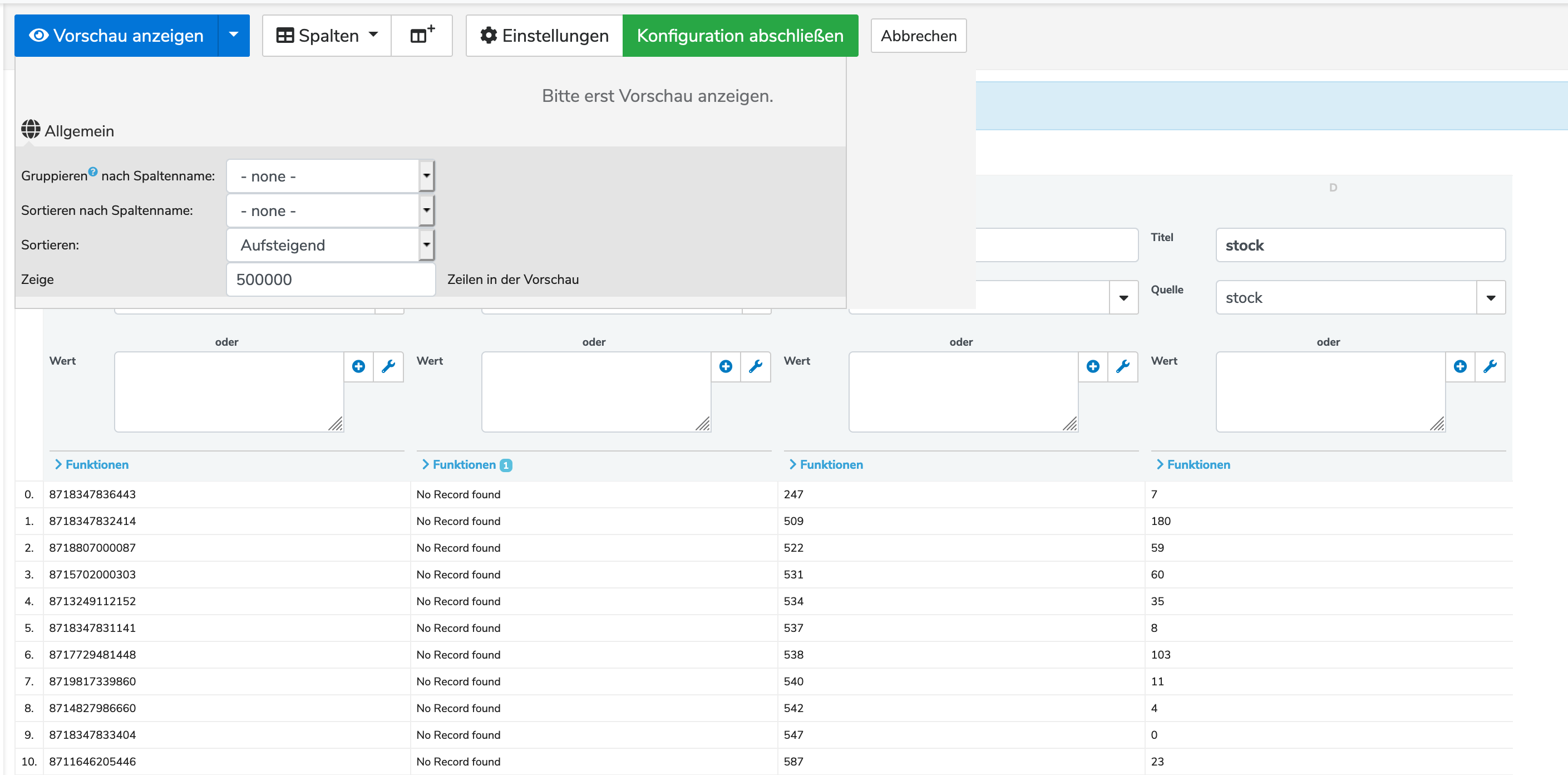
wie sieht es eigentlich in dem Mapper aus, in dem du den Querverweis machst. Lass dir bitte mal in dem Mapper über „Einstellungen“, so 500.000 Zeilen anzeigen. Also einfach mehr als du in der CSV hast.
Da kannst du dann mal drüber fliegen, oder nach einer bestimmten EAN(8719817986323) mit Strg+F suchen, ob es ein Ergebnis in der Spalte VariantID gibt.
Des Weiteren würde ich dich auch bitten mal einen Screenshot von deiner Querverweiskonfiguration zu machen.
Viele Grüße,
Lukas
Hallo Lukas,
ich kann leider nicht nach der EAN suchen, da mir ja immer nur 100 Zeilen angezeigt werden und ich jede weitere 100 Zeilen aufklicken muss. Auch wenn ich in den Einstellungen „Zeige“ den Wert „500.000“ eingegeben habe.
Hier ist nochmal der Querverweis:
LG
Sascha
Hallo Sascha,
hast du anschließend auch nochmal auf „Vorschau anzeigen“ geklickt? Denn normalerweise sollten dann die maximale Anzahl an Zeilen angezeigt werden.
Alternativ kannst du auch mal den exportierten Flow als Json in einem Support-Ticket schicken.
Viele Grüße,
Lukas
Hi Lukas,
auch wenn ich 500 sage, zeigt er mir noch 99 an.
Sage ich 50, zeigt er mir 49 Zeilen an.
Also, die Funktion funktioniert schon, nur leider kappt euer System die Vorschau ab 100 Zeilen.
Auch beim Download der vollständigen Anzeige bekomme ich nur die 100 Zeilen angezeigt:
Soll ich den exportierten Flow als Json unter einer ID im Ticket vermerken?
LG
Sascha
Hallo Lukas,
Ticket wurde gerade aufgemacht!
Hätte nicht gedacht, dass es alles so schwierig ist.
Danke für Deine tolle und schnelle Hilfe.
LG
Sascha