Hi, wir ziehen Produktinformationen aus Shopify und möchten dabei die Zuordnung von images zu den variants herausfinden. Laut Shopify REST API ist diese Zuordnung eindeutig gegeben. Beim Aufruf von shopifyGetProducts in unserem Flow gibt es jedoch nur ein Feld „item_images“, das alle Bilder des Products enthält. Wie finde ich aber das der jeweiligen Variante zugeordnete Bild heraus?
Hallo @SteffenClaus,
die exakte Zuordnung der Bilder zu den Varianten bekommst du mit dem Step shopifyGetProductImages. An Ende der Tabelle findest du die Spalte „image_variant_ids“, in der die VariantenIDs aufgelistet werden, die das entsprechende Bild gesetzt haben.
Viele Grüße
Lukas
Hey, vielen Dank! Hatte ich übersehen. Ich war offenbar fälschlicherweise davon ausgegangen, dass in der spalte „item_images“ direkt die der Variante zugeordneten Bilder zu finden sind. Gibt es denn eine Möglichkeit, dass ich alles in einem File habe (das würde unseren Import übersichtlicher machen)?
Hallo @SteffenClaus,
du könntest das Ergebnis des GetImages Step in einen Datastore schreiben. Danach kannst du in einem Flow mit dem GetProducts Ergebnis im Mapper per Querverweis mit der VariantenID in einer neuen Spalte die Variantenimages holen.
https://docs.synesty.com/SSUD/Datastores.html#datenimport-und-export
https://docs.synesty.com/SSUD/Spreadsheets.html#querverweis
Viele Grüße
Lukas
Ich bin offensichtlich zu blöd. Ich habe meinen Flow erweitert und das Ergebnis von GetImages in einem Datastore abgelegt. Leider ist es mir unmöglich, im Mapping-Step nach Downloaden von GetProducts auf den Inhalt der Spalte von „image_src“ zuzugreifen. Ich habe jeglichen Querverweis-Zugriff mittels id, id2 oder id3 probiert (weder product_id noch id noch variant_ids führen zu einem Match).
Ergänzung: Der Flow funktioniert, wenn ich z.B. die Product-ID exakt spezifizieren. Sobald ich aber einen Vollabruf machen will, dann erhalte ich folgende Warnung: Letzte Meldung: Error row #1000: Error writing to datastore in row 1000 (identifier: 36664680382714): identifier3 too long. Current value 36072141979816,36072142012584,36072142045352,36072142078120,36072142110888,36072142143656,36072142176424,360721422419… is longer th. Ich speichere hier im identifier3 die variant_id des Abrufes von GetImages (damit ich nachher darauf zugreifen kann).
Weiß jemand, wie ich die Spaltengröße des identifiers3 vergrößern kann? Leider schlägt hierdurch der komplette Flow fehl, wenn manche Images von sehr vielen Variants genutzt werden.
Hallo @SteffenClaus,
die identifier3 Spalte (und auch identifier und identifier2 Spalten) sind fest auf 100 Zeichen begrenzt. Gibt es einen bestimmten Grund warum du alle VariantenIDs in der identifier3 Spalte brauchst ?
Du könntest dir auch eine neue Spalte (z.B. VariantIDs) im Schema des Datastores hinzufügen und die Varianten IDs in dieser Spalte speichern.
Viele Grüße
Torsten
Ich brauche die VariantIDs, um beim späteren Querverweis auf diese zuzugreifen und letztendlich den image_src für eben diese VariantID zu bekommen.
Wie sieht denn der Querverweis aus?
Auf eine Komma separierten Liste von Varianten IDs im identifier3 kann mit einer einzelnen Varianten ID kein Querverweis ausgeführt werden. Ich vermute dass für jede Variante (VariantenID) ein eigener Datensatz im Datastore notwendig ist. Damit kann dann auch ein Querverweis pro Varianten ID ein Querverweis gemacht werden.
Um die Komma separierte Liste von Varianten IDs in einzelne Zeilen aufzutrennen, könnte der ColumnSplitToRows Step verwendet werden.
Das Splitten kann aber doch erst erfolgen nachdem die Quelldaten in den Datastore geschrieben wurden, richtig? Und der Fehler bez. der Spaltengröße taucht während des Schreibens in den Datastore auf. Das hier ist der Querverweis, der aus Basis der VariantID versucht, aus dem zuvor mit GetProductImages befüllten Datastore die image_src Spalte herauszuziehen.
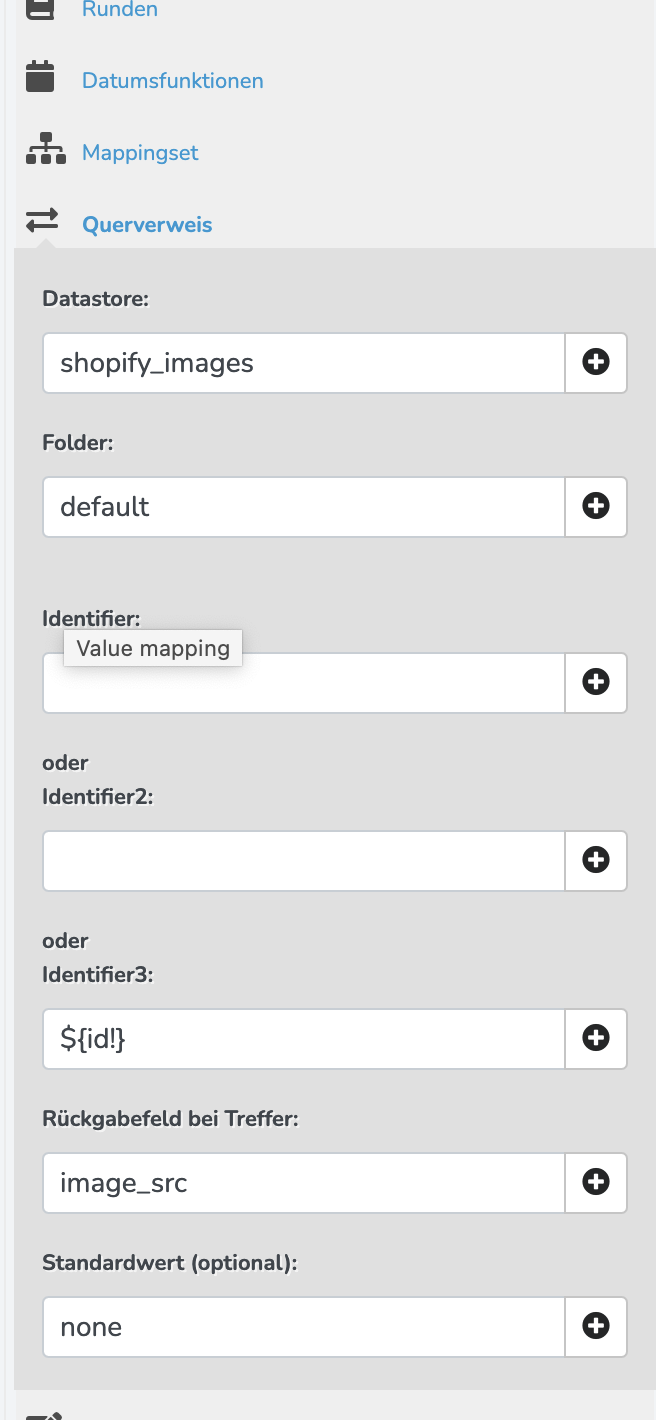
Nein, das Splitten (nach Varianten IDs) müsste nach dem ShopifyGetProductImages und vor dem DatastoreWriter passieren. Damit wird ein neues Spreadsheet mit einer Zeile pro Varianten ID erstellt. Die Varianten ID Spalte sollte dann vermutlich als identifier (nicht identifier3) im Datastore verwendet werden. Damit sollte dann pro Varianten ID eine Zeile im Datastore erstellt werden.
Ja, der Fehler kommt erst beim Import in den Datastore. Wenn die Spalte vorher „gesplittet“ wurde, sollte die max. Länge nicht mehr überschritten werden.
Der Querverweis müsste dann noch entsprechend angepasst werden. Das ${id!} müsste dann in das identifier Feld.