Hallo Tim,
die Beschreibung des SpreadsheetUrlDownload Steps ist leider nicht korrekt. Der Step unterstützt nur SPREADSHEET und keine SPREADSHEETLIST. Wir korrigieren die Beschreibung des Steps.
Der einfache Fall: Anzahl der Preislisten bekannt
Wenn du die Anzahl der Preislisten kennst, kannst du natürlich pro Preisliste ein Filter Step (für die Filterung der Zeilen der jeweiligen Preisliste) und pro Preisliste einen SpreadsheetUrlDownload verwenden.
Der schwierigere Fall: Anzahl der Preislisten unbekannt
In diesem Fall könntest du dir die queries für den SpreadsheetUrlDownload vorab in einem TextHTMLWriterMultiOutput Step zusammenbauen.
Im template des TextHTMLWriterMultiOutput „läufst“ du über den Output des SpreadsheetSplitter Steps und erzeugst nach 250 Zeilen oder am Ende des Spreadsheets eine Datei (einfache CSV Datei mit einer Spalte).
Beispiel template
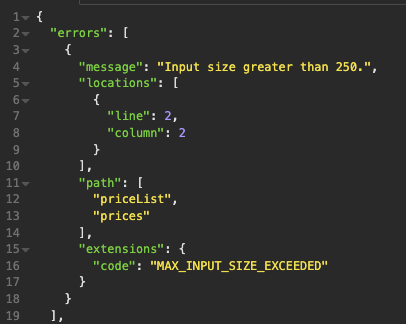
Die query hab ich nicht getestet, Spaltenamen und SpreadsheetSplitter outputkey (spreadsheetList@SpreadsheetSplitter_5) musst du anpassen.
<#assign maxBatchSize = 250>
<#assign queryStart = "body\nmutation { priceListFixedPricesAdd(" />
<#assign queryEnd = "] ){ prices { variant{ id }, price{ amount, currencyCode } } } } " />
<#assign requestNum = 0 />
<#list spreadsheetList@SpreadsheetSplitter_5 as priceList>
<#assign numberRows = 0>
<#list priceList.getRows() as row>
<#if fileContent == "">
<#assign fileContent>${queryStart}priceListId: ${row.get("priceList")}, prices : [ </#assign>
</#if>
<#assign request> { variantId: ${row.get("variantId")}, price: { amount: ${row.get("price")}, currencyCode: EUR} }<#sep>,</#assign>
<#assign numberRows += 1>
<#assign fileContent += request >
<#if (numberRows >= maxBatchSize)>
<#assign fileContent += queryEnd>
<#assign requestNum += 1 />
${output(fileContent, ("request_" + requestNum + ".csv"), "UTF-8")}
<#assign fileContent = "" />
<#assign numberRows = 0>
</#if>
</#list>
<#assign fileContent += queryEnd >
<#assign requestNum += 1 />
${output(fileContent, ("request_" + requestNum + ".csv"), "UTF-8")}
<#assign fileContent = "" />
</#list>
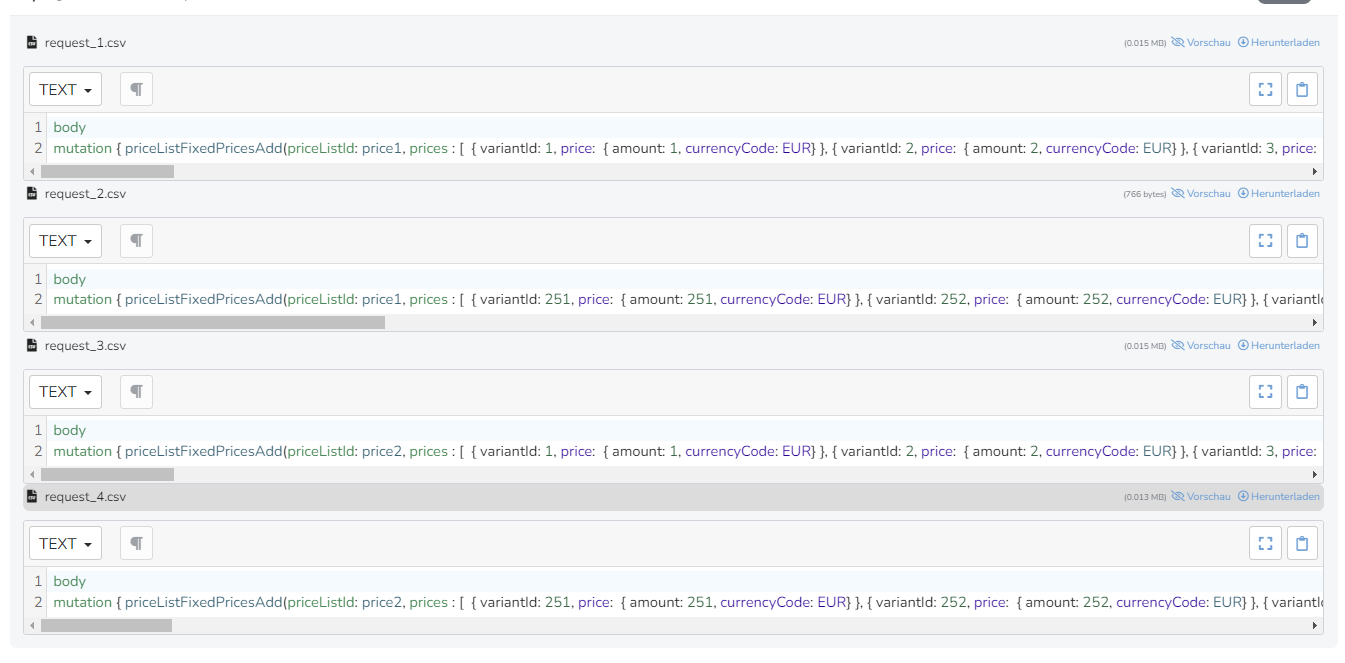
Als Ergebnis erhälts du dann mehrere CSV Dateien die du mit dem CSVReader Step einlesen kannst.
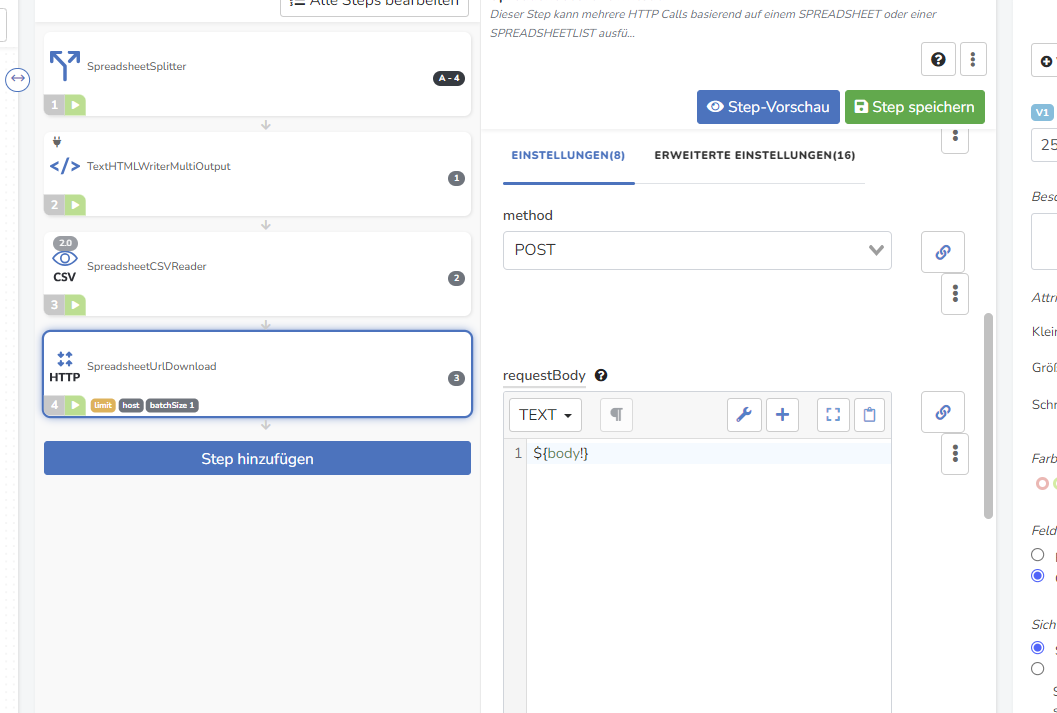
Dieses Spreadsheet kannst du dann als input im SpreadsheetUrlDownload Step verwenden (mit batchSize=1 und requestBody = ${body} )
VG Torsten
Edit: Screenshot vom Flow