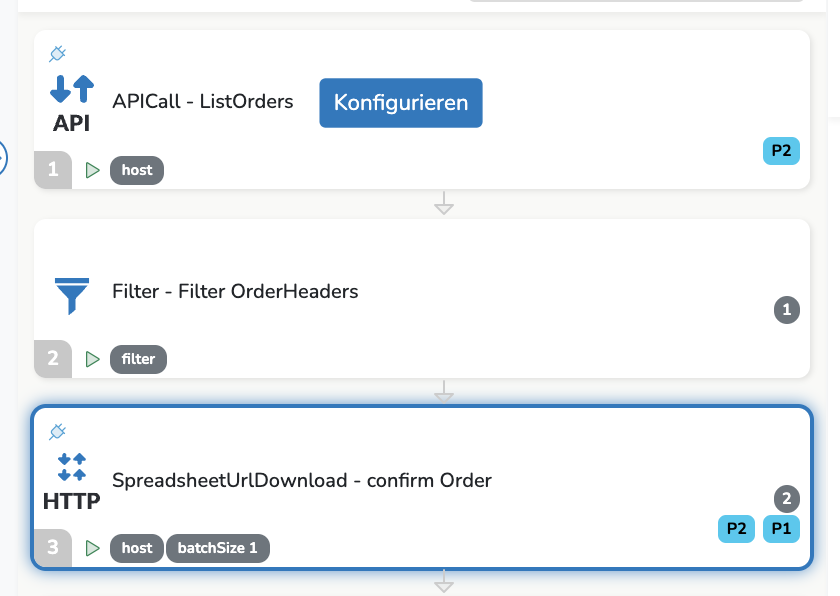
in einem TextHTMLWriter wurde verifiziert dass ich die Order IDs auslesen und in einer JSON anzeigen lassen kann
ich habe auch versucht den Step von neu aufzubauen
Beides erfolglos und ein Fehler ist für mich nicht erkennbar. Der Flow hat die ganze Zeit funktioniert und ist seit mehreren Monaten im Betrieb. Die Bestellungen müssen dringend reinlaufen. Ein manueller Import ist nicht möglich.
Vielleicht könntest du auch mal deine fertige Payload hier posten, damit man sich die näher anschauen kann.
Wahrscheinlich ist der Fehler aber folgender:
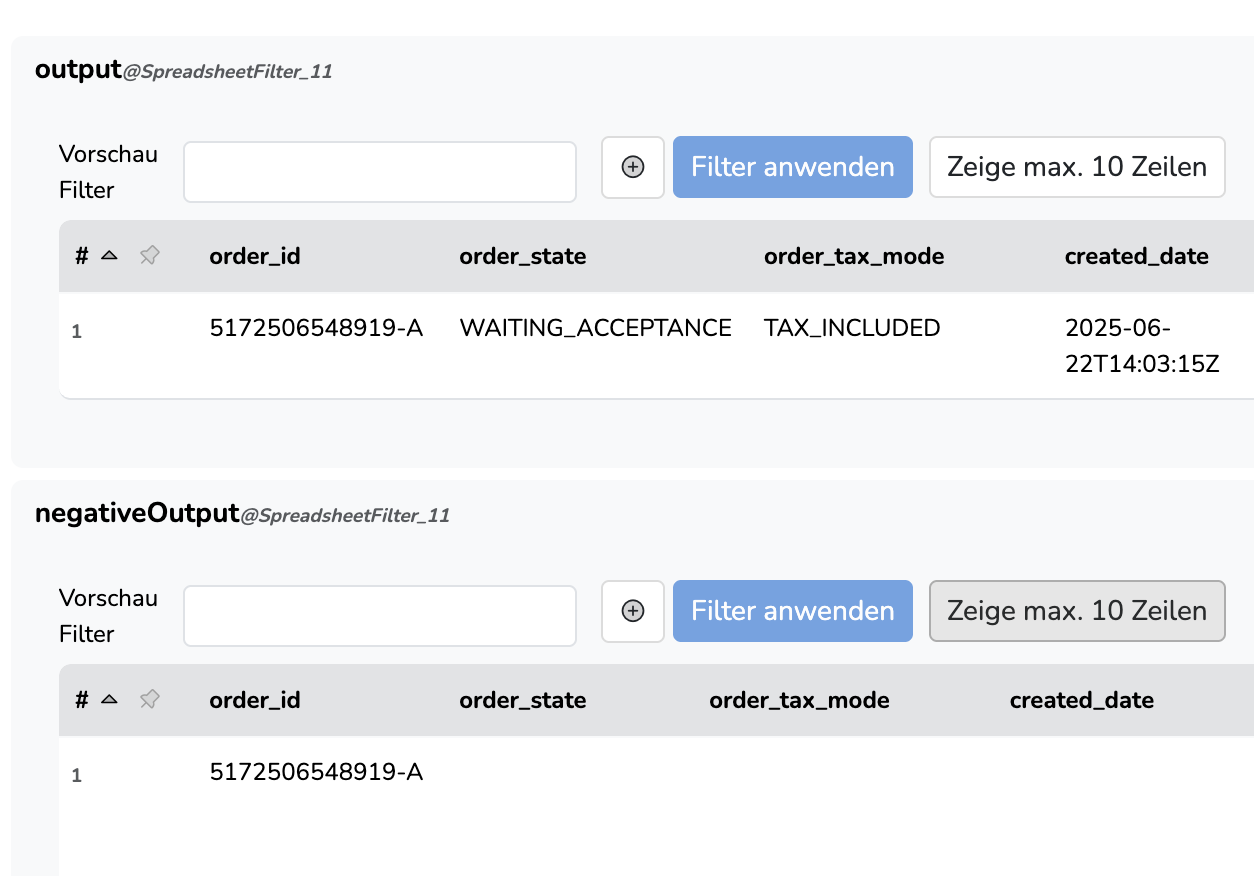
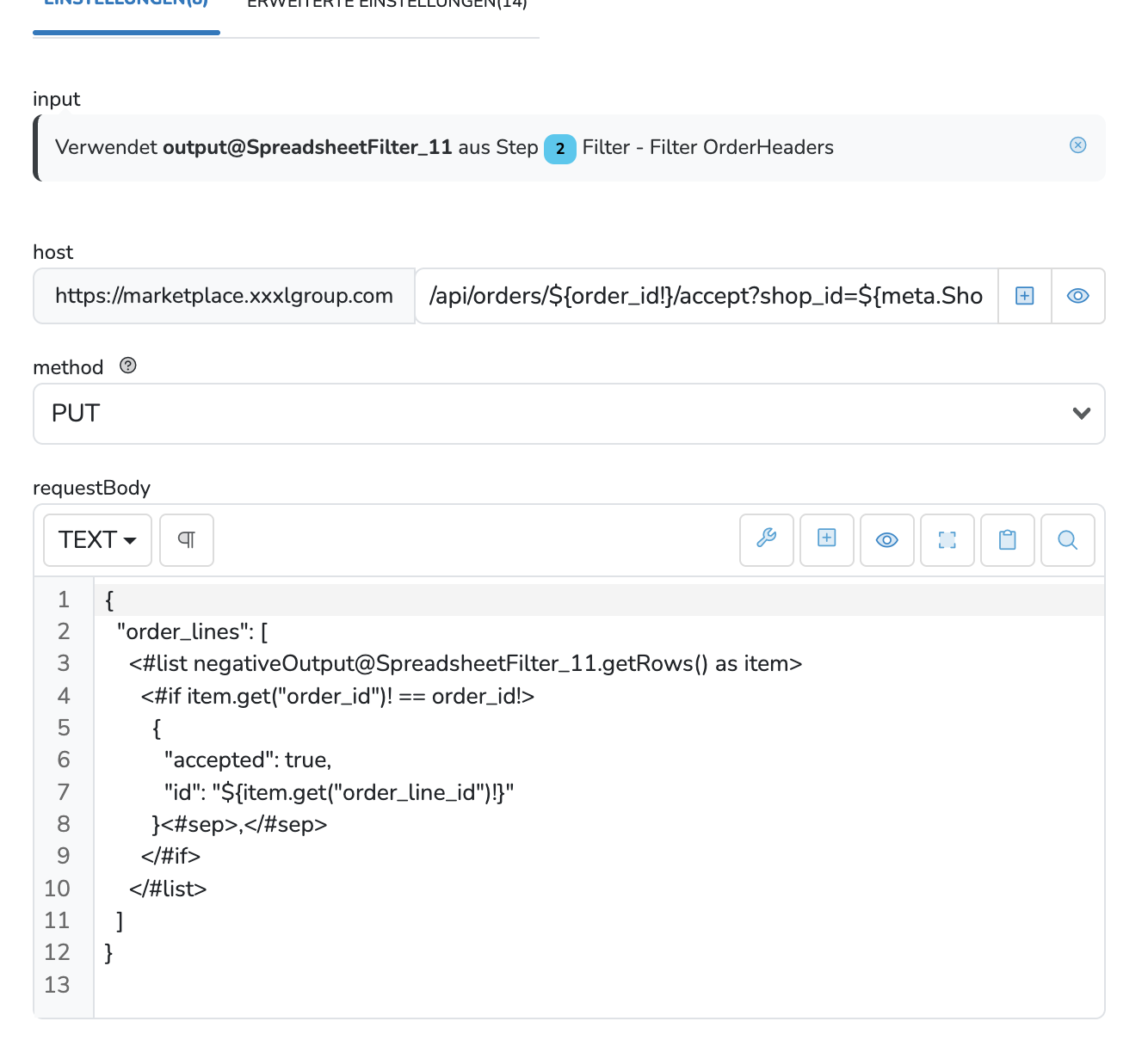
Wenn der Check item.get("order_id") == order_id beim letzten Element negativ ist, dann hast du immer noch das , vom vorherigen Element drin, obwohl es kein entsprechendes order_line Objekt gibt.
Das daraus resultierende JSON wäre somit invalide.
Dieser Fehler sollte eigentlich immer in dem Moment auftreten wo du mehrere Orders in einem Flow-Run zu verarbeiten.
Noch eine weitere Anmerkung:
Dein Approach mit dem Header und Positionen splitten und dann darüber zu iterieren scheint recht ineffizient.
Angenommen jede Order hat eine Position und du hast 10 Orders. Du würdest somit also 10*10 → 100 checks haben ob deine Order_ID matched.
Mein Vorschlag wäre es statt dessen, die Positionen vorher in einem Mapper zu guppieren und das Order_Line JSON direkt im Mapper zu gestalten und dann später in das SpreadsheetUrlDownload zu integrieren.
Siehe folgendes Beispiel:
Ich denke, dass @sHelme mit seiner Vermutung (siehe „Wahrscheinlich ist der Fehler aber folgender:“) richtig liegt. Zum Testen kannst du auch das Limit im SpreadsheetUrlDownload mal auf 1 setzen und dir den requestBody im Vorschau - Ergebnis anschauen.
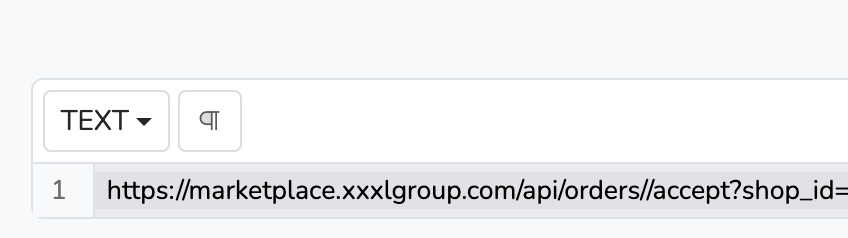
Das ist aktuell noch ein Problem der input Vorschau des SpreadsheetUrlDownload. Die Daten aus dem input Spreadsheet sind bei der Vorschau des inputs nicht vorhanden, sodass sie immer leer ausgegeben werden (in deinem Fall ${order_id!} ).
In der Step Vorschau sollte aber die vollständige url vorhanden sein.
nur noch ein Tipp zum Debuggen:
Du kannst temporär bei den Fehlercodes im SpreadsheetURLDownloader nur die 500 eintragen. Dann sorgen deine 400er Fehler nicht mehr für einen Flowabbruch und du kannst dir die abgeschickten Requests in eine Excel schreiben und ausgeben lassen.