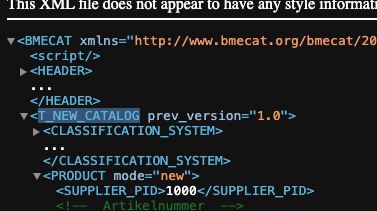
Hallo zusammen,
ich habe eine BMEcat-XML-Datei, die ich in Excel speichern möchte. Ich brauche dafür aber etwas Unterstützung.
Für jedes Produkt in der Datei sind folgende Daten hinterlegt:
Struktur
<PRODUCT>
<SUPPLIER_PID>12345</SUPPLIER_PID>
<PRODUCT_DETAILS>
<DESCRIPTION_SHORT>Kurze Beschreibung</DESCRIPTION_SHORT>
<INTERNATIONAL_PID type="EAN">54321</INTERNATIONAL_PID>
<ERP_GROUP_BUYER>2158</ERP_GROUP_BUYER>
</PRODUCT_DETAILS>
<PRODUCT_FEATURES>
<REFERENCE_FEATURE_SYSTEM_NAME>Lieferant</REFERENCE_FEATURE_SYSTEM_NAME>
<REFERENCE_FEATURE_GROUP_ID>2158</REFERENCE_FEATURE_GROUP_ID>
</PRODUCT_FEATURES>
<PRODUCT_FEATURES>
<REFERENCE_FEATURE_SYSTEM_NAME>AllgemeineEigenschaften</REFERENCE_FEATURE_SYSTEM_NAME>
<FEATURE>
<FT_IDREF>1</FT_IDREF>
<FVALUE>2500</FVALUE>
</FEATURE>
<FEATURE>
<FT_IDREF>2</FT_IDREF>
<FVALUE>2500</FVALUE>
</FEATURE>
</PRODUCT_FEATURES>
<PRODUCT_FEATURES>
<REFERENCE_FEATURE_SYSTEM_NAME>ZusatzstoffeUndAllergene</REFERENCE_FEATURE_SYSTEM_NAME>
<FEATURE>
<FT_IDREF>32</FT_IDREF>
<FVALUE>true</FVALUE>
</FEATURE>
<FEATURE>
<FT_IDREF>36</FT_IDREF>
<FVALUE>true</FVALUE>
</FEATURE>
<FEATURE>
<FT_IDREF>29</FT_IDREF>
<FVALUE>true</FVALUE>
</FEATURE>
</PRODUCT_FEATURES>
<PRODUCT_FEATURES>
<REFERENCE_FEATURE_SYSTEM_NAME>Naehrstoffe</REFERENCE_FEATURE_SYSTEM_NAME>
<FEATURE>
<FT_IDREF>6</FT_IDREF>
<FVALUE>2.9</FVALUE>
<FUNIT>G</FUNIT>
</FEATURE>
<FEATURE>
<FT_IDREF>3</FT_IDREF>
<FVALUE>728</FVALUE>
<FUNIT>KJ</FUNIT>
</FEATURE>
<FEATURE>
<FT_IDREF>2</FT_IDREF>
<FVALUE>175</FVALUE>
<FUNIT>KK</FUNIT>
</FEATURE>
</PRODUCT_FEATURES>
<PRODUCT_ORDER_DETAILS>
<ORDER_UNIT>CT</ORDER_UNIT>
<CONTENT_UNIT>C62</CONTENT_UNIT>
<NO_CU_PER_OU>4</NO_CU_PER_OU>
<QUANTITY_MIN>1.000</QUANTITY_MIN>
<QUANTITY_INTERVAL>1.000</QUANTITY_INTERVAL>
</PRODUCT_ORDER_DETAILS>
<PRODUCT_PRICE_DETAILS>
<PRODUCT_PRICE price_type="net_customer">
<PRICE_AMOUNT>99.99</PRICE_AMOUNT>
<PRICE_CURRENCY>EUR</PRICE_CURRENCY>
<TAX>0.07</TAX>
<PRICE_BASE>
<PRICE_UNIT>CT</PRICE_UNIT>
</PRICE_BASE>
</PRODUCT_PRICE>
</PRODUCT_PRICE_DETAILS>
<USER_DEFINED_EXTENSIONS>
<UDXZutaten>XXX.</UDXZutaten>
<UDXProduktbeschreibung>YYY</UDXProduktbeschreibung>
<UDXZubereitung>ZZZ</UDXZubereitung>
</USER_DEFINED_EXTENSIONS>
</PRODUCT>
Das Zielergebnis sollte so aussehen:
| SKU code | Supplier Description | Price | Case | Pack | Unit | Measure | Minium Order Quantity | Zusatzstoff 1 | Zusatzstoff 2 | Nährstoff 1 | Nährstoff 2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [SUPPLIER_PID] | [Description Short] | [PRICE_AMOUNT] | 1 | [NO_CU_PER_OU] | [FVALUE]* | [CONTENT_UNIT] | QUANTITY_MIN | [FVALUE]** | [FVALUE]** | [FVALUE] & [FUNIT]*** | [FVALUE] & [FUNIT]*** |
| 12345 | Kurze Beschreibung | 99,99 | 1 | 4 | 2500 | C62 | 1 | true | true | 2.9 G | 728 KJ |
*[FVALUE]: aus
Allgemeine Eigenschaften
<REFERENCE_FEATURE_SYSTEM_NAME>AllgemeineEigenschaften</REFERENCE_FEATURE_SYSTEM_NAME>
<FEATURE>
<FT_IDREF>1</FT_IDREF>
<FVALUE>2500</FVALUE>
**[FVALUE] aus
Zusatzstoffe
<REFERENCE_FEATURE_SYSTEM_NAME>ZusatzstoffeUndAllergene</REFERENCE_FEATURE_SYSTEM_NAME>
<FEATURE>
<FT_IDREF>32</FT_IDREF>
<FVALUE>true</FVALUE>
***[FVALUE] & [FUNIT] aus
Naehrstoffe
<REFERENCE_FEATURE_SYSTEM_NAME>Naehrstoffe</REFERENCE_FEATURE_SYSTEM_NAME>
<FEATURE>
<FT_IDREF>6</FT_IDREF>
<FVALUE>2.9</FVALUE>
<FUNIT>G</FUNIT>
Die erste Zeile in der Tabelle zeigt die Quelle der Daten (wird im echten Export natürlich nicht drin sein). Die zweite Zeile zeigt die eigentlichen Werte von unserem Beispiel.
Meine Fragen:
- Gibt es einen Weg, immer auf die gleiche FVALUE zu verweisen (also immer auf die Value für FT_IDREF = 1 im ersten Fall, auf die Value für FT_IDREF = 32 im zweiten Fall usw)? Wenn ich es richtig verstehe, listet der Mapper alle FVALUEs mit einer aufsteigenden Zahl auf:
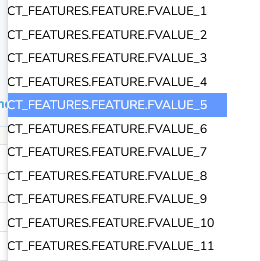
Nicht jedes Produkt hat aber die gleiche Anzahl an Features, deswegen bekomme ich dann gemischte Ergebnisse:

Also anstatt dass ich immer z.B. das Nettogewicht zu bekommen, habe ich manchmal Nettogewicht, dann Allergeneninfo, dann Fettgehalt auf 100g.
-
Kann ich irgendwie anstatt Zusatzstoff 1 usw. in der Spaltenüberschrift den FT_IDREF haben, bzw. der Wert, der ihm gegenüber steht? Z.B. ID = 32 = Fettgehalt → Spaltenüberschrift „Fettgehalt“.
-
Kann ich die Drop-Down-Felder im Mapper irgendwie breiter machen? Oder das, was man da sieht, bereits im XMLReaderVisual bereits irgendwie abkürzen? Wie man vom Screenshot oben sieht, sind die Namen der einzelnen Kategorien ziemlich lang, weswegen ich den Regler ständig hin und her schieben muss. Das ist bei längeren Listen echt mühselig. Diese Frage hat die niedrigste Prio.
Ich freue mich auf euren Input. Sagt gerne Bescheid, wenn etwas unklar ist oder ihr zusätzliche Infos braucht.
Viele Grüße
Maya