Ich habe viele Steps und Mapper, welche Daten via master[‚some_name‘] referenzieren und filtern. Da aber gerade die Performance von Filtern sehr langsam ist, würde ich gerne fragen, ob Querverweise schneller sind und, wenn es darum in Filter Steps anhand dieser Daten zu filtern.
Hallo @davidadamswmhde,
das wird sich kaum unterscheiden. Für beide wird eine extra Abfrage in der Datenbank gemacht/benötigt. Tendenziell sollte der Zugriff über master[‚spalte‘] minimal schneller sein.
Wenn du sehr viele anschließende Filter oder Mapper Steps verwendest, die auf diese referenzierten Daten zugreifen, würde ich die empfehlen den Cache Mode in diesem Mapper zu aktivieren. Ansonsten werden die Daten mehrfach aus der Datenbank geholt.
Im letzten Blog Eintrag ist auch eine kurze Erläuterung dazu: Und wie wirkt sich das auf die Performance aus? (Teil 1) - Synesty Studio - E-Commerce - Datenfeeds - Schnittstellen - Automatisierung
Viele Grüße
Torsten
Hallo Torsten,
wir verwenden die Referenz master[‚some_name‘] direkt im Filter, und speziell diese benötigen sehr lange mittlerweile. Wäre es dann evtl. günstiger zuerst die Daten zu holen, dann in einem Spreadsheet die Daten aus dem Master zu ergänzen, das Spreadsheet zu cachen und anschließend darüber zu filtern?
Exakt so war die Antwort meines Kollegen gemeint.
Die Idee ist, sich im Spreadsheet alles so zusammenzubauen, worüber man später filtern möchte. Dann diese Spreadsheet cachen (man kann sich das vorstellen, dass das Ergebnis dann in einer CSV-Datei geschrieben wird und damit fixiert ist).
Danach dann die Filterung auf das gecachte Spreadsheet machen.
Alternativ könnte man sich auch die Filterbedingungen nochmal anschauen, und prüfen, ob man ggf. einige „billigere“ Checks nach vorne (links) holen kann. Die Filterbedingen werden von links nach rechts ausgewertet und sind bei Verwendung von && fail-fast.
Beispiel:
statt der Bedingung
master['someColumn'] && isAvailable! == "Ja"
könnte man umgedreht schreiben:
isAvailable! == "Ja" && master['someColumn']
Im Falle von isAvailable==„Nein“, würde master[‚someColumn‘] gar nicht ausgeführt werden und damit auch kein Datenbankzugriff.
Update: Bedingung im Beispiel oben korrigiert (aus Nein, Ja gemacht).
Ok, ich muss mir das mal anschauen. Wir haben aktuell große Problme beim Filtern von einem Datastore mit ca. 50k Einträgen, das dauert mitunter mehrere Minuten, was in Folge zu sehr langen Laufzeiten der Jobs führt.
Nur der Vollständigkeit halber: sie können auch gern mal ein Support-Ticket dazu eröffnen, und ein Kollege schaut sich das konkret bei Ihnen mal an und versucht Tips zu geben, falls er etwas findet.
Ok, ich hab mal verglichen zwischen den beiden Methoden:

Der Job mit dem Filter über die gecachte Tabelle geht schneller, aber das erstellen der gecachten Tabelle aus einem Datastore mit 59.000 Einträgen dauert sehr lange (3 Minuten). Hier werden 3 Felder aus dem Master Datastore mittels ${master[some_name]} befüllt.
Immerhin schon etwas.
Können Sie ggf. mal noch einen Screenshot des Datenfluss-Graphen schicken? zu erreichen über:
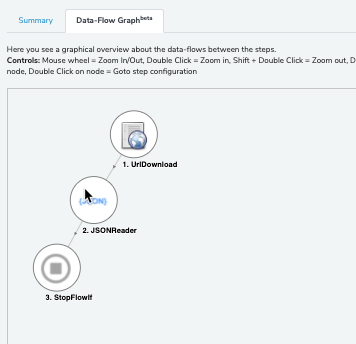
Evtl. kann da noch etwas draus ableiten, wenn man sieht, welche Steps die Outputs wie verwenden.
Ansonsten fällt uns jetzt nur noch ein, dass man die Daten des Masters schon beim Schreiben an die Children mit dran schreibt (z.B. beim schreiben der Children)… damit spart man sich dann beim lesen den Master-Lookup.
Frage ist auch, ob man immer über alle 59.000 Einträge rennen muss. Aber da kennen sie ihren Usecase besser.