Hallo,
ich bin auf der Suche nach einem eleganten Weg eine XML Datei von Sonderzeichen zu bereinigen bzw. diese zu ecapen.
Ich habe zwar den Step FileFindAndReplace gesehen, allerdings ist der wohl nicht mit dem TextHTMLWriter kompatibel. Die XML Dateien werden damit nämlich dynamisch erstellt.
Ich hab es aktuell zwar so gelöst:
<artikelbez>${(position.get("ItemLabel")!"")?replace("&", "&")?replace("\"", """)}</artikelbez>
Allerdings wird das sehr schnell ziemlich aufgeblasen und unübersichtlich. Daher suche ich eine etwas bessere Lösung (falls es die gibt  )
)
Viele Grüße,
Patrick
Hallo @abc_design,
dann sollte ${escapeHTML('')!} die Funktion sein die du suchst. Damit kannst du zwar immer noch nicht eine komplette Datei escapen aber zumindest die Werte, bei denen du weißt, dass da Zeichen zum escapen drin sind.
Also in deinem Beispiel müsste es dann so aussehen:
<artikelbez>${escapeHTML(position.get("ItemLabel"))!}</artikelbez>
Viele Grüße
Lukas
Moin @abc_design,
hast du ein Spreadsheet als input?
Dann könntest du einmal folgendes machen:
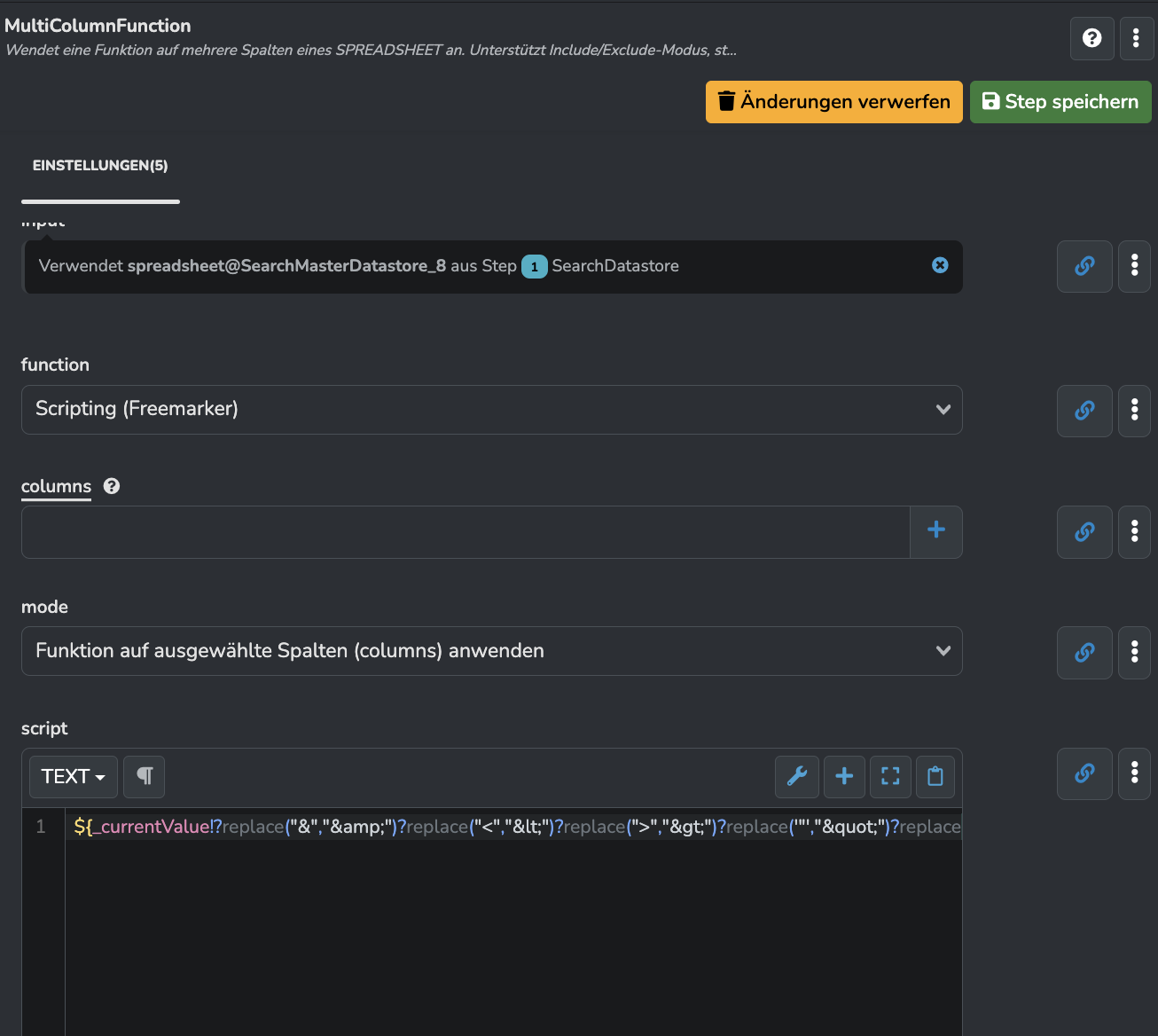
MultiColumnFunction Step mit dieser Funktion:
${_currentValue!?replace("&","&")?replace("<","<")?replace(">",">")?replace('"',""")?replace("'","'")}
und dann daraus das XML generieren 
Beste Grüße
Tim
1 „Gefällt mir“
Hallo @synesty-Lukas,
das Problem mit ecapeHTML ist, dass das auch Umlaute als HTML Entität ersetzt, was wiederum das XML nicht valide macht.
Der Vorschlag von @EG-Interfaces sieht auch ganz gut aus. Danke dafür!
Allerdings setzt sich die XML aus mehreren Spreadsheets zusammen, daher wird das vielleicht auch etwas viel. Ich werds aber mal ausprobieren.
Danke euch.
Viele Grüße,
Patrick
Hallo Patrick,
ich hänge mich auch mal noch mit einer Idee rein.
Eventuell kannst du den Inhalt auch einfach in einen CDATA Abschnitt packen, z.B.:
<artikelbez><![CDATA[${position.get("ItemLabel")!}]]></artikelbez>
Der Inhalt des CDATA Blocks sollte vom XML Parser als Text übernommen werden. Damit könntest du dir eventuell die komplette Bereinigung der Sonderzeichen sparen.
VG Torsten
1 „Gefällt mir“