ich habe eine Frage zum Aktualisieren von Daten in einem datastore mit Querverweis.
Ich habe eine Tabelle mit identifier (Gutschriftsnummer) und identifier2 (Bestellnummer). Diese Tabelle möchte ich mit Auftragsdaten aus meinem ERP-System Plentymarkets aktualisieren, es liegen dabei jedoch nur die Informationen zur Bestellnummer (identifier2) vor und nicht die Gutschriftsnummer. Da bei einem Update scheinbar immer der identifier benötigt wird, habe ich mit einem Querverweis gearbeitet, welcher die Gutschriftsnummer (identfier) aus der bestehenden Tabelle auf Basis der Bestellnummer (identifier2) sucht und somit ein Update ermöglicht. Das Problem ist, dass die Bestellnummer nicht unique ist, da es zu einer Bestellung mehrere Gutschriften und somit auch mehrere Gutschriftsnummern geben kann. Dadurch wird allerdings immer nur der erste Datensatz aktualisiert, da der Querverweis immer das erste Suchergebnis zurückgibt.
Ist es möglich Aktualisierungen vorzunehmen ohne den identifier zu nutzen und nur auf Basis von identifier2 zu arbeiten?
Alternativ würde es mir auch helfen, wenn bei einem Querverweis nur die Vorgänge aus einem bestimmten Prozessstatus berücksichtigt werden. Das ist aber auch nicht möglich, oder?
Du könntest den SearchInDatastoreByIdentifiers Step verwenden, um alle Datensätze mit dem identfier2 (Bestellnummer) aus dem Datastore zu holen.
Das Ergebnis des SearchInDatastoreByIdentifiers kannst du mit dem Filter Step auch filtern (processingstatus). Die beiden Ergebnis-Spreadsheets (PlentySearchOrders & gefiltertes SearchInDatastoreByIdentifiers Spreadsheet) kannst du mit dem SpreadsheetAppend Step zusammenführen und in einem Mapper Step gruppieren, sodass du den gewünschten identifier bekommst.
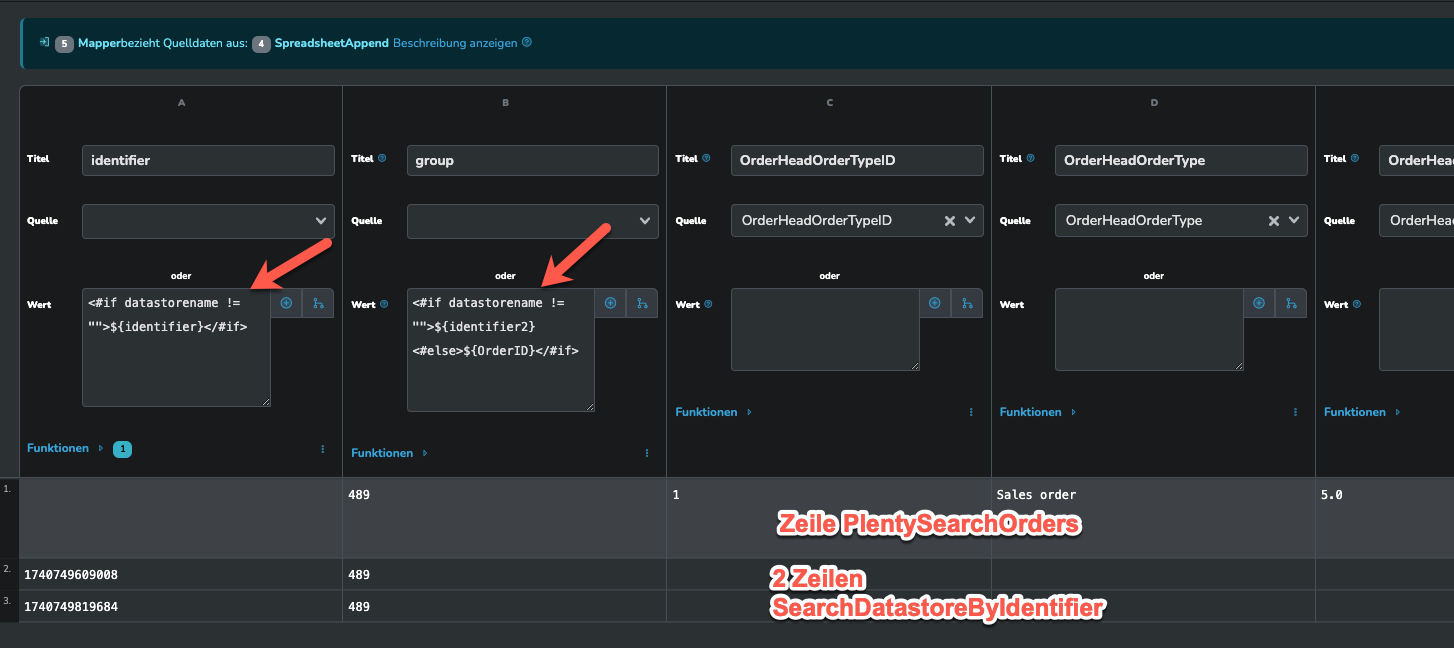
vielen Dank für die Hinweise. Ich habe die Steps eingebaut und hänge jetzt an dem Punkt, an dem ich die Daten zusammenfügen möchte. Ich habe bspw. aus der Datenbank zwei Zeilen bekommen und möchte jetzt die Daten aus Plenty (1 Zeile) ergänzen. Die beiden Datenquellen habe ich mit SpreadsheetAppend zusammengefügt und als Ergebnis drei Zeilen bekommen - ich brauche aber 2 zeilen, mit den daten aus beiden Datenquellen. Du schreibst, dass mit einem Mapper-Step die Daten gruppiert werden können. Wie schaffe ich das? Kann ich damit die Daten aus Zeile3 in die Zeilen1 und Zeilen2 übernehmen?
ich bin vorhin davon ausgegangen, dass du immer nur eine Zeile im entsprechenden processingstatus hast. Es geht auch mit mehreren Zeilen, macht es aber etwas komplizierter.
Im Mapper Step fügst du dir eine Hilfsspalte ein (group), die du zum gruppieren verwendest. Als Wert kannst du hier eine Bedingung verwenden die dir bei den PlentySearchOrders Zeilen die OrderID und bei den Datensätzen identifier2 ausgibt. In der identifier Spalte fügst du eine Bedingung ein, die nur bei den Datensätzen des Datastores den identifier ausgibt.
Das sollte dann in etwa so aussehen:
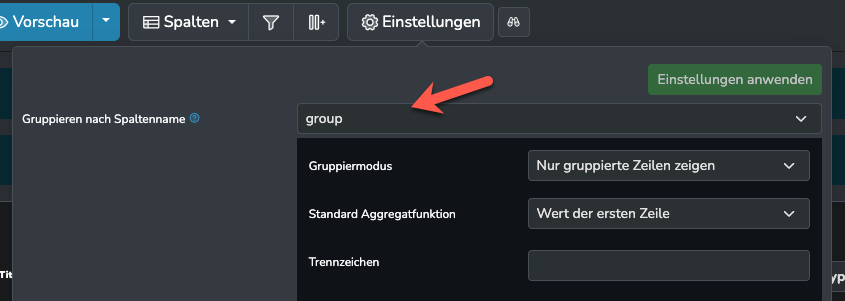
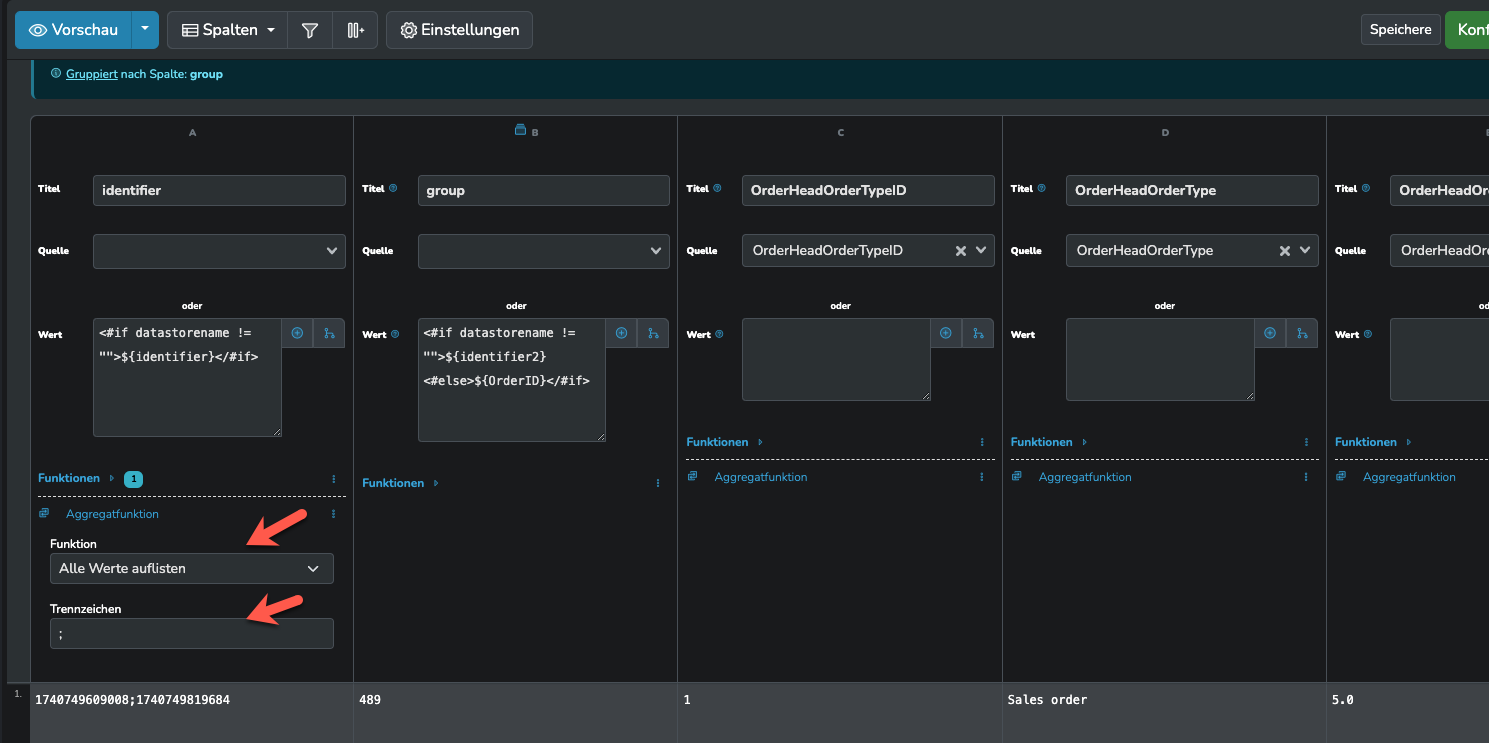
Dann noch in der identifier Spalte als Aggregatfunktion „Alle Werte auflisten“ und ein Trennzeichen angeben, dass nicht in deinem identifier vorkommen kann (z.B. ;). Nach der Gruppierung solltest du eine Zeile sehen, mit den PlentySearchOrders Daten und in der identifier Spalte die beiden identifer der Datensätze.
Wenn du nur eine oder wenige Spalten aus dem PlentySearchOrders Ergebnis in den Datastore schreiben willst, dann würde ich dir empfehlen die nicht benötigten Spalten zu entfernen.
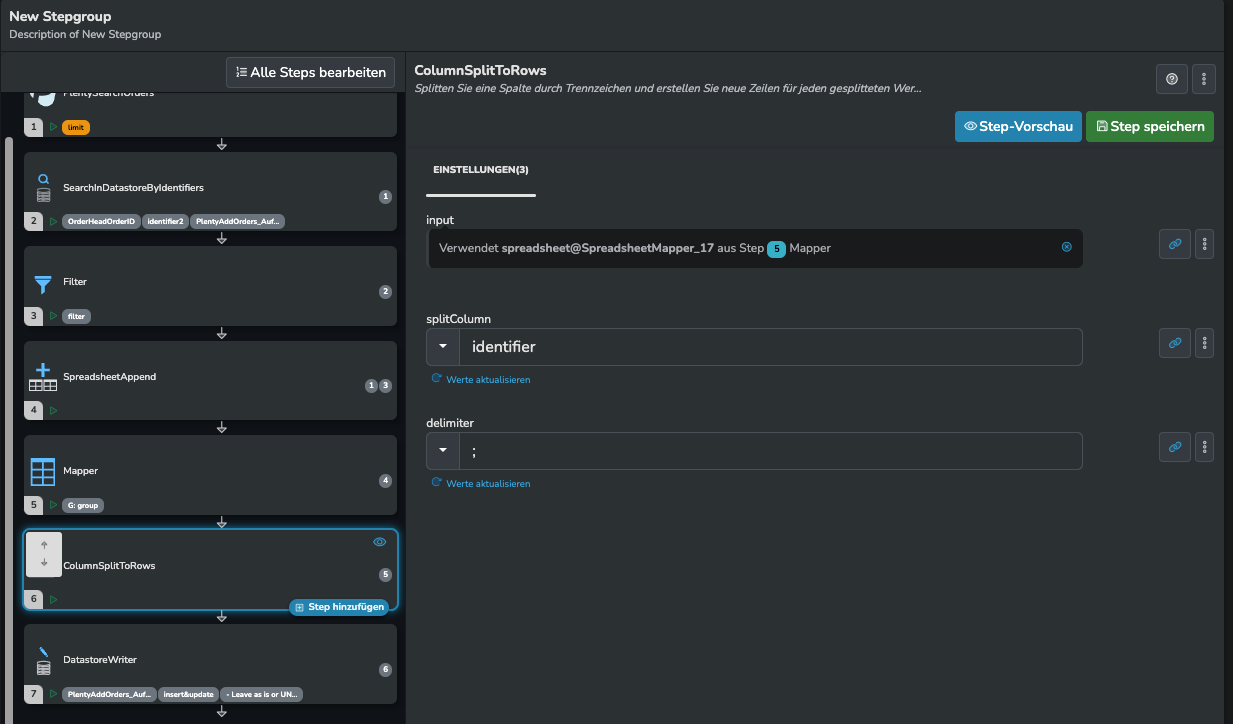
Danach fügst du im Flow noch den Step ColumnSplitToRows mit folgenden Einstellungen ein.
Das sorgt dafür, dass pro identifier ein Zeile erstellt wird. Das Ergebnis kannst du dann im DatastoreWriter Step für den Import verwenden.