ich bin bei dem Step PlentySetItemTexts durch die große Datenmenge auf Probleme durch die Rest API Limits gestoßen.
Nun würde ich gern die Auswertung (Response) des Steps in ein Datastore schreiben. Beziehungsweise welche ID geklappt hat und welche nicht.
Mir ist bekannt welche Outputs der Step zurück gibt, wenn ich ein Wert reinschreibe und es SUCCESS ist. Steht ja auch in der Doku.
Aber wie verhält sich das bei einem ERROR?
Oder habt ihr vielleicht ein Beispiel Flow.
Vielen Dank und Grüße
Henry
Nachtrag:
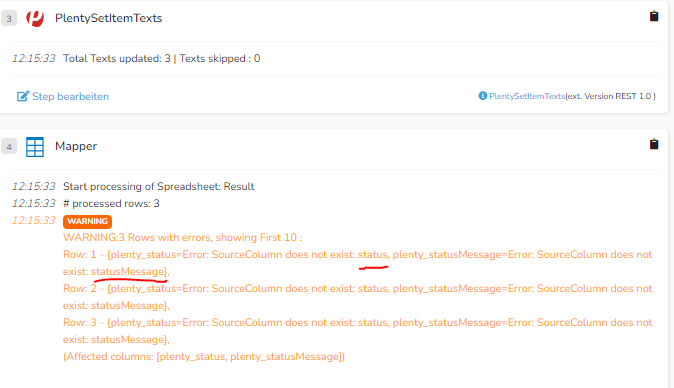
In der Step-Vorschau komme ich an die Werte von ‚status‘ und ‚statusMessage‘ in dem nachfolgenden Mapper ran. Aber beim Flow Durchlauf kriege ich folgende Warnung und der anschließende DB-Writer macht nichts.
Aktuell sind im Output Spreadsheet nur die erfolgreichen (SUCCESS) Zeilen vorhanden. Das unterscheidet sich an der Stelle leider von der Vorschau. Wir versuchen das nochmal etwas zu überarbeiten und auch die Fehlerhaften Zeilen in einem extra Spreadsheet bei der Ausführung auszugeben.
Das wäre Prima.
Oder wie werden aktuell die REQUESTs von der API Schnittstelle ausgewertet?
Kommen dann die selben Variablen nur OHNE Werte zurück.
Bräuchte ein Merkmal oder Index woran ich gescheiterte Anfragen erkennen kann.
aktuell sind im output Spreadsheet nur die erfolgreich angelegten bzw. aktualisierten Texte vorhanden. D.h. es werden nur eine Zeilen mit den Daten aus der Response im Output ausgegeben, wenn wir den Status 200 als Antwort erhalten
Alle input Zeilen, die durch unsere Validierung (z.B. fehlendes Pflichtfeld wie VariantID) bzw. einen Status 401 als Antwort von der API erhalten, sind nicht im Output vorhanden.
danke für die Antwort.
Und wie verhält sich das wenn die Validierung OK ist und die API-Schnittstelle ein Fehler zurück schickt.
Wie zum Beispiel beim Limit-Problem, wo plenty sagt es sind zu viele Anfragen in einer bestimmten Zeit?
Kommt bei so einem Request dann auch alle Felder(Zeilen)? Schön wäre wenn nicht.
Im besten Falle kriege ich den Status, dies kommt aber vielleicht mal irgendwann bei euch.
Wenn ich mir das nicht Merke, kommt ja wieder das Limit-Problem.
Du verstehst mein Problem?
Wenn wir von der API einen Fehler als Antwort bekommen (Status >= 400, also z.B. bei Call Limit erreicht oder nicht vorhandene Varianten ID / Item ID), dann wird dafür keine Zeile im Output Spreadsheet hinzugefügt. D.h. du kannst davon ausgehen, dass für alle Varianten / Zeilen des output Spreadsheets die Texte gesetzt wurden.
Das Limit für die Calls / Minute (ShortPeriodLimit) sollte im Normalfall kein Problem darstellen, da wir dieses Limit in unserem API Client schon „abfangen“. Falls das bei dir auftritt, dann laufen vermutlich einige Flows parallel. Das könnte man eventuell durch Anpassung der Startzeiten der Flows vermeiden.
Falls das tägliche API Call Limit (LongPeriodLimit) Probleme macht, wäre es sinnvoll pro Run immer nur eine bestimmte Anzahl von Texten zu setzen (festes ‚limit‘ im Step setzen) und sich die erfolgreich gesetzten zu „merken“. Wenn ich dich richtig verstanden habe, willst du genau das machen. Wie oben geschrieben kannst du das output Spreadsheet des Steps dafür verwenden. Alles was darin enthalten ist, wurde erfolgreich gesetzt.
Ja es sind die „LongPeriodLimit“ weil es ca. 55000 Einträge sind.
Dies wird auch nur einmalig sein, weil dann immer nur Artikel aktualisiert werden. Aber den ersten Run muss ich durch kriegen.
Wenn alle erfolgreichen im Spreadsheet von PlentySetItemTexts sind wäre es ja sehr gut und ich kann damit was anfangen.
Dann müsste nur noch dieser BUG behoben werden BUG bei PlentySetItemTexts? damit ich mir den entsprechenden „Identifier“ bauen kann, um den Process_Status des Datensatzes anzupassen.