Unsere Synesty „Sprechstunde“ (siehe Ankündigungen) findet alle 2 Wochen statt und bietet Kunden, Partnern und Interessenten die Möglichkeit Fragen zu stellen und Neuigkeiten zu Synesty zu erfahren.Agenda:- Begrüßung- Gast mit Kurzpräsentation /…
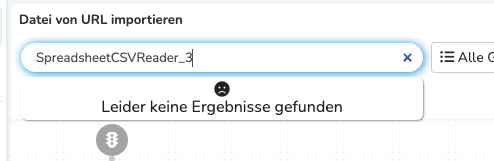
(statt „keine Ergebnisse gefunden“ sollte natürlich etwas kommen)
zusätzlich würden wir versuchen die interne Step-ID mal noch irgendwie am Step einzublenden (evtl. beim Überfahren mit der Maus (da müssen wir aber erstmal etwas experimentieren, was da gut aussieht, ohne alles mit IDs zuzukleistern)
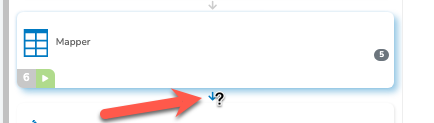
der „kleine Pfeil“ unter den Steps, welcher die Step-Outputs anzeigt
Wie könnte man das offensichtlicher machen, dass man den anklicken kann und dass sich dahinter die Beschreibung der Outputs verbirgt? Scheinbar ist das einigen nicht klar. Gibt es eine bessere Möglichkeit? (muss ja nicht der Pfeil sein.) Evtl. ein Button oder Badge? Oder sollte sich der Pfeil beim Überfahren des Steps mit der Maus irgendwie hervorheben, so dass man sieht, dass man den anklicken kann?
Feedback willkommen. Gern auch von Usuability-Experten wie @samenhaus-admin
P.S. das andere Thema, dass die Filter-Outputs (für positiv und negativ) im Mapper gleich heißen gehen wir an.
Wie könnte man das offensichtlicher machen, dass man den anklicken kann und dass sich dahinter die Beschreibung der Outputs verbirgt? Scheinbar ist das einigen nicht klar.
Entweder als Tooltip über den Pfeil oder links unten über der Stepzahl (vergleichbar zur Pill eines referenzierten Steps rechts)
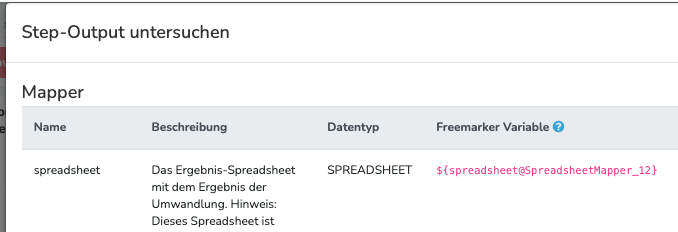
„Dieser Step hat den folgenden Output:
spreadsheet@SpreadsheetMapper_146
unmappedValues@SpreadsheetMapper_146
errors@SpreadsheetMapper_146“
Wenn’s n Tooltip wird, dann würde ich den Help-Cursor beibehalten, ansonsten eher den Pointer bevorzugen. Da macht’s vielleicht eher ‚Click‘
Mir würde es schon genügen, wenn man beim Anlegen eines Steps die PermaID an den Stepnamen anfügt. Z.B. anstatt Mapper → Mapper_12. Das es dann ein SpreadsheetMapper ist weiß man irgendwann.
Gibt es hierfür ein Changelog oder wurde lediglich die UI umgestaltet?
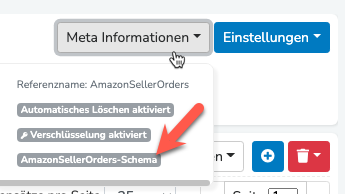
Hierzu ein Feedback: Im alten UI war es möglich, über die Datastore-Settings direkt in das verwendete Schema zu navigieren. Das war afaik an folgender Stelle:
Der kommt noch Aber jaein: Wir haben die technologische UI-Basis „modernisiert“ und in dem Zuge auch versucht das UI zu entschlacken und zu optimieren. D.h. Platz (hoffentlich) besser ausnutzen und UI-Performance bei vielen Daten verbessern.
Das haben wir in die Meta-Informationen umgezogen.
Hallo,
mein Fehler hat zwar nichts mit den Datastores zu tun. Ich wollte nur Fragen ob Ihr auch etwas an den TextHTML-Writer geändert habt. Der Flow hat die ganze Zeit ohne Fehler funktioniert, erst zu Ostern kam der Fehler: Fehler beim Parsing der 50. Datei splitXMLFile49.xml. In den meisten Fällen ist die Datei leer, kaputt oder ist inhaltlich fehlerhaft, so dass Sie nicht geparst werden kann. (Root Causes: NoSuchFileException: /xxx/splitXMLFile49.xml)
Der Mapper davor liefert die korrekten Ergebnisse. Mir kommt es so vor das es sich um einen Time-Out handelt. Zwischendurch sind ein paar Flows durchgelaufen (ca. 2 Stunden Laufzeit). Die Flows mit Fehler sind ca. 6 Stunden gelaufen. Ich kann mir nicht wirklich erklären woher der Fehler kommen soll.
Wie gesagt nur eine Frage.
temporäre Dateien werden von uns 6h lang gespeichert. Daher auch der Fehler, wenn der Flow länger als 6h läuft. Denn nach 6h sind die erstellten Dateien nicht mehr vorhanden.
Hallo Lukas,
danke für die Antwort. Ich verstehe nicht warum der Flow ab und zu „hängt“ und dann so lang braucht. Heute morgen lief er wieder normal durch. Kannst Du bitte dazu etwas sagen?
Hallo Lukas,
ich habe die Handwerker zu Hause und konnte mich nicht kümmern.
Ja, es betrifft Billo-Schuhe und zwar den Flow „Artikel von HIS holen und in Plenty anlegen“. Dieser hat seit dem 12.4. Aussetzer. Wobei er ab dem 18.4. gar nicht mehr komplett durchläuft. Ich hatte aber gar keine Änderungen mehr am 12.4. (bzw. 11.4.).
leider können wir es noch nicht genau datieren. Wir sind schon jeden Tag in Kontakt mit unseren Serverhost um eine Lösung zu finden.
Das Problem tritt ja bei dir auf, da wir temporäre Dateien nach 6h löschen. Vielleicht ist es dir als Workaround möglich, die temporäre Datei zu einem späteren Zeitpunkt im Flow zu erstellen oder die Datei temporär auf einem FTP hochladen und später zur Verarbeitung wieder runterladen.
Hallo @synesty-Lukas,
vielleicht liegt hier ein Missverständnis vor. Die Datei braucht eigentlich nicht 6 Std. im Speicher zu sein, sondern der Flow ist normalerweise nach ca. 2 Std. fertig. Daher hatte ich auch vorher nie ein Problem. Ich möchte ja wissen warum der Flow hängen bleibt.
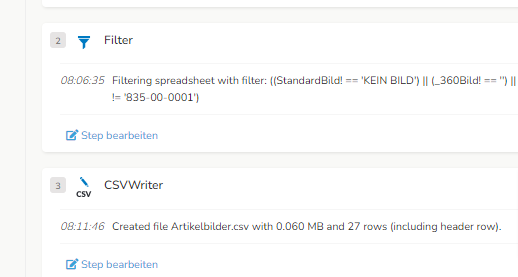
Ich habe ein Support Ticket eröffnet, weil langsam eine Lösung gefunden werden muss. Wie schon im Ticket geschrieben finde ich den Step CSV-Writer extrem langsam. Für 27 Zeilen sollte dieser nicht 5 Minuten brauchen.
Momentan erstellt er eine Datei mit 40000 Zeilen, dafür braucht der Step dann 123 Stunden???
Jetzt ist die CSV doch erstellt worden: Laufzeit etwas über 1 Stunde für 43300 Zeilen (18MByte).
Die nächste Datei mit 333 Zeilen (nur 8 kByte) hat er in einer Sekunde erstellt.
@synesty-Lukas
Jetzt hängt er wieder bei der Erstellung einer Datei mit 44000 Zeilen und erwarteten ca. 6 MByte Größe. Diese erstellt er seit 12:44 Uhr. Also tatsächlich läuft der Flow daher viel langsamer als früher.
Ist das nur bei uns der Fall?
Ich bin mir inzwischen ziemlich sicher das es nur an der Geschwindigkeit liegt. Das Erstellen der CSV Dateien per CSV Writer ist um den Faktor 3 langsamer geworden. Da innerhalb des Flows mehrere große Dateien erstellt werden hat das große Auswirkung. Ich habe das Erstellen der letzten Datei (nur Kontrolldatei) abgeschaltet. Eventuell reicht das um den Flow durchlaufen zu lassen. Sonst kann ich nicht mehr als Workaround machen. Es wird halt eine große XML-Datei (48 MB) in viele kleine CSV umgewandelt.
Wir melden uns im Laufe des Nachmittags nochmal per Ticket bei dir. Es gibt aktuell ein technisches Problem, an deren Analyse und Lösungsfindung wir dran sind, aber noch keine Lösung haben. Und ja es liegt an der Geschwindigkeit…dies ist genau das Problem.
Versuch evtl. mal noch folgendes:
CacheMode in allen Mapper und Filtern aktivieren, die in irgendeiner Form etwas mit Datastores machen (z.B. Querverweise).
Steps die am Anfang des Flows gemacht werden, die aber erst am Ende des Flows benötigt werden, evtl. auch nach unten schieben , da wo sie gebracht werden